
Yapeng Tian
Assistant Professor, The University of Texas at Dallas
yapeng.tian@utdallas.edu
ECSS 4.211
Bio
I am an Assistant Professor in the Computer Science Department of UT Dallas and lead the Computer Vision and Multimodal Computing (CVMC) Lab. Before coming to UTD, I finished my PhD at University of Rochester, advised by Chenliang Xu, my master degree at Tsinghua University working with Wenming Yang, and B.E degree at Xidian University. I was a visiting student at SIAT advised by Yu Qiao. I did internships at Adobe Research with Dingzeyu Li and Meta with Alexander Richard. I am interested in solving core computer vision, computer audition, and machine learning problems and applying the developed learning approaches to broad AI applications, such as multisensory perception, computational photography, AR/VR, accessibility, and healthcare. My work has been recognized with awards including the AAAI New Faculty Highlights, Cisco Faculty Research Award, and Amazon Research Award.
Research Highlights
-
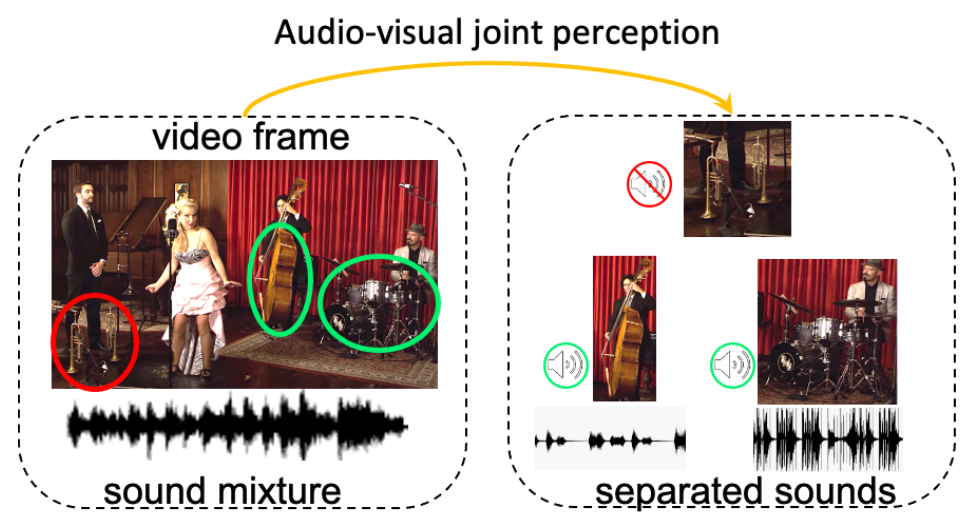
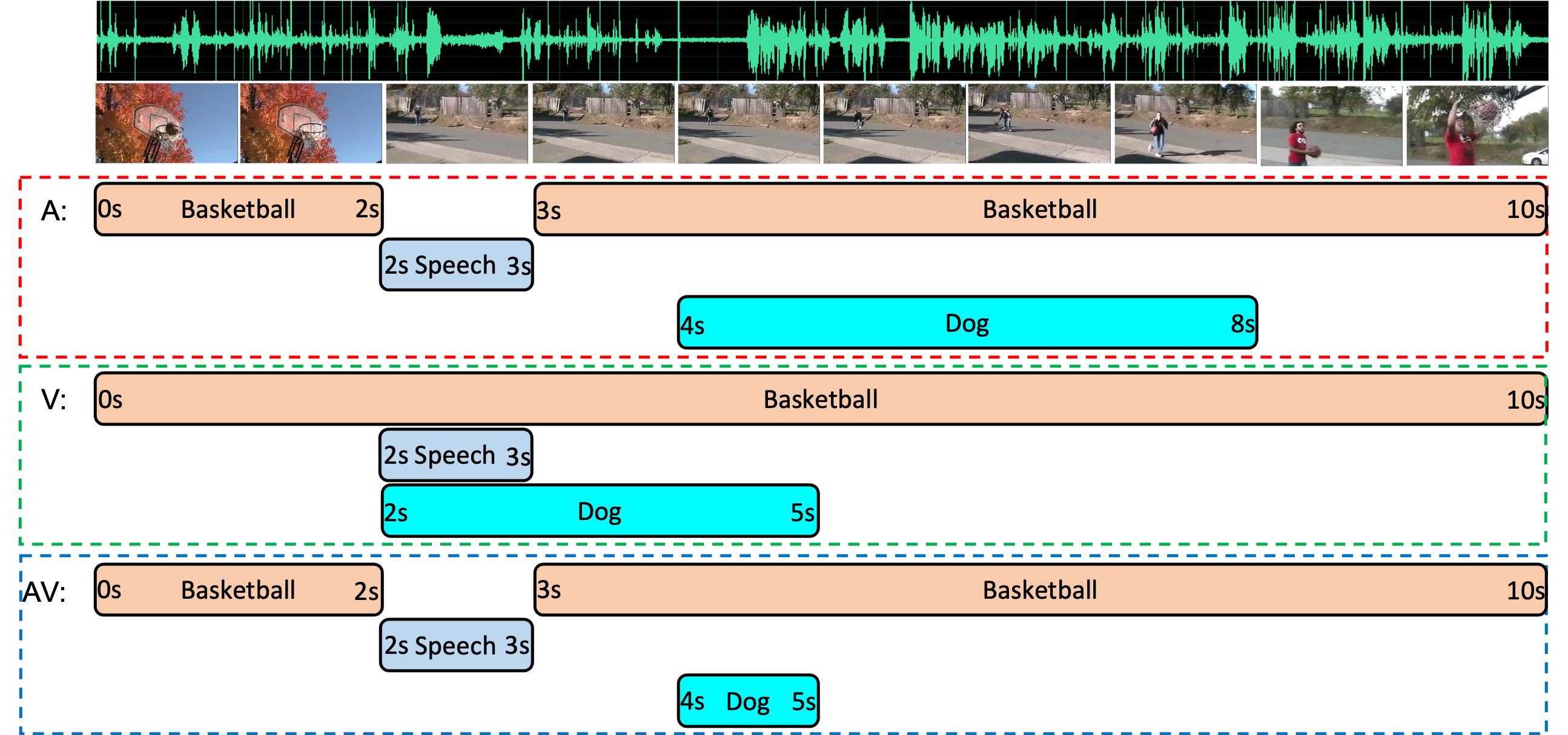
Audio-Visual Scene Understanding: To achieve truly intelligent systems, we must move beyond scene understanding that relies solely on individual senses like sight or sound. Our research pioneers a multimodal approach, integrating computer vision and audition to unlock the rich information available through combined audio-visual perception. We tackle fundamental challenges in this emerging field, developing unified, explainable, and robust multimodal models for video understanding.
Audio-Visual Scene Generation: We're pushing beyond scene perception to content creation, developing audio-visual intelligent systems that can generate realistic sounds and videos from diverse multimodal inputs. Our work includes joint audio-visual generation, spatial audio generation, and video and text guided audio generation models.
AI for Accessibility and Healthcare: We develop computer vision and AI models to empower individuals with disabilities and improve healthcare. Our work spans: (a) Assistive Technologies: Creating systems to aid those with autism, blind or low vision, and hearing impairments. (b) Medical Imaging: Developing AI to enhance medical images for improved diagnosis and treatment.
Image and Video Processing: I enjoy building computer vision algorithms to improve image and video quality in both automated and creative ways. My research involves developing a range of image and video restoration models capable of generating photorealistic outputs. This work has also been applied to medical imaging, including MRI data.
News
|
Students
Students at UTD:
Siva Sai Nagender Vasireddy (PhD student)
Shijian Deng (PhD student)
Saksham Singh Kushwaha (PhD student)
Weiguo Pian (PhD student; co-advised with Dr. Yunhui Guo)
Jia Li (PhD student)
Xinpeng Li (PhD student)
Lujing Xie (PhD student; co-advised with Dr. Xiwei Tang)
Zexin Xu (PhD student; co-advised with Dr. Wei Yang)
Zijun Cui (PhD student)
Collaborated External Students:
Tianyu Yang (PhD student at University of Notre Dame)
Shentong Mo (PhD student at Carnegie Mellon University)
Kai Wang (PhD student at University of Toronto)
Alumni:
Vaishnavi Josyula (Undergraduate, School of Natural Sciences & Mathematics, Fall 2025)
Michael Yang (K12; Summer 2023-2025; Next Undergraduate at Columbia University)
Ziru Huang (Visiting student; Tsinghua University; 2024)
Yiyang Nan (Graduate student at Brown University; Spring 2023-2024; Next: researcher at Cohere for AI)
Matthew Wang (K12; Summer 2023-2024, Next Undergraduate at Cornell University)
William Doan (Undergraduate; Fall 2023 - Summer 2024; Jonsson School of Engineering and Computer Science Award; Next: PhD student at UTD's CS Theory Group)
Zeke Barnett (K12; Parish Episcopal School at Dallas, Spring 2023 - Spring 2024; Next Undergraduate at CMU)
Anikait Bharadwaj (K12; Frisco ISD; Spring 2024)
Aditya Kulkarni (Undergraduate; Spring 2023; Next Meta)
Atmin Mehul Sheth (Undergraduate at UTD; 2023)
Yuxin Ye (Graduate student at Tsinghua University)
Yichen Chi (Graduate student at Tsinghua University)
Junhao Gu (PhD student at Tsinghua University)
Jiamiao Zhang (Graduate student at Tsinghua University)
Hai Wang (Graduate student at Tsinghua University; next: PhD student at UCL)
Sen Fang (Undergraduate at Victoria University, Next: PhD student at Rutgers University)
Sasha Kaplan (Undergraduate; Spring 2023)
Sisi Aarukapalli (Undergraduate; Summer 2023)
Harsh Singh (PhD student at UTD; Spring and Summer 2023; Next: CV MSC at MBZUAI)
Yulang Wu (Graduate student at UTD CS, Spring 2023; Next: Postdoc at University of California San Francisco)
Publications
Most recent publications on Google Scholar.
‡ indicates equal contribution.
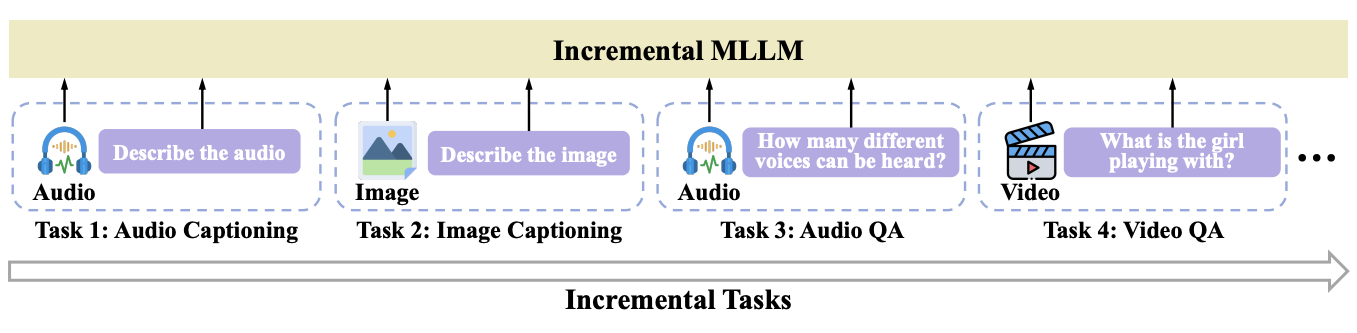
Modality-Inconsistent Continual Learning of Multimodal Large Language Models
Weiguo Pian, Shijian Deng, Shentong Mo, Mingrui Liu, Yunhui Guo, Yapeng Tian
TMLR'26: Transactions on Machine Learning Research.
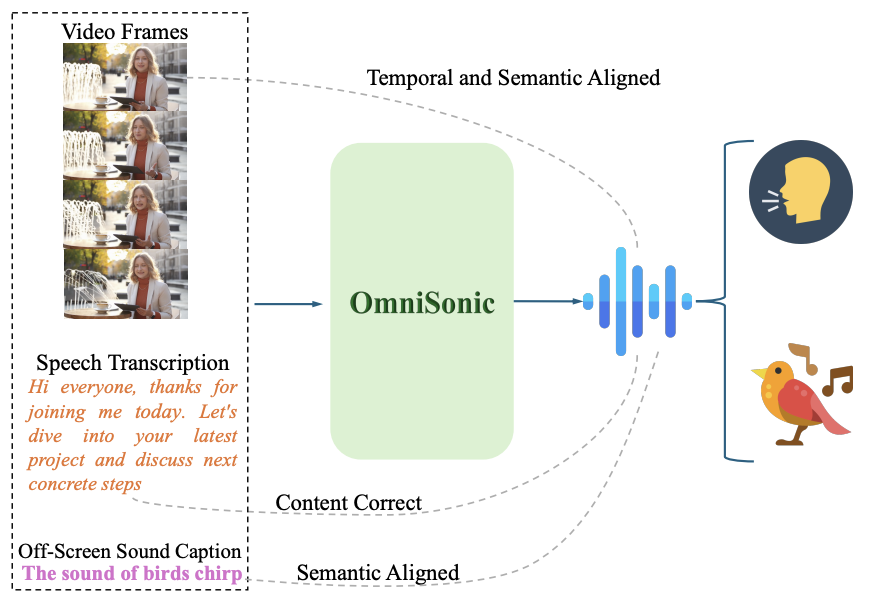
OmniSonic: Towards Universal and Holistic Audio Generation from Video and Text
Weiguo Pian, Saksham Singh Kushwaha, Zhimin Chen, Shijian Deng, Kai Wang, Yunhui Guo, Yapeng Tian
CVPR'26: IEEE/CVF Conference on Computer Vision and Pattern Recognition.
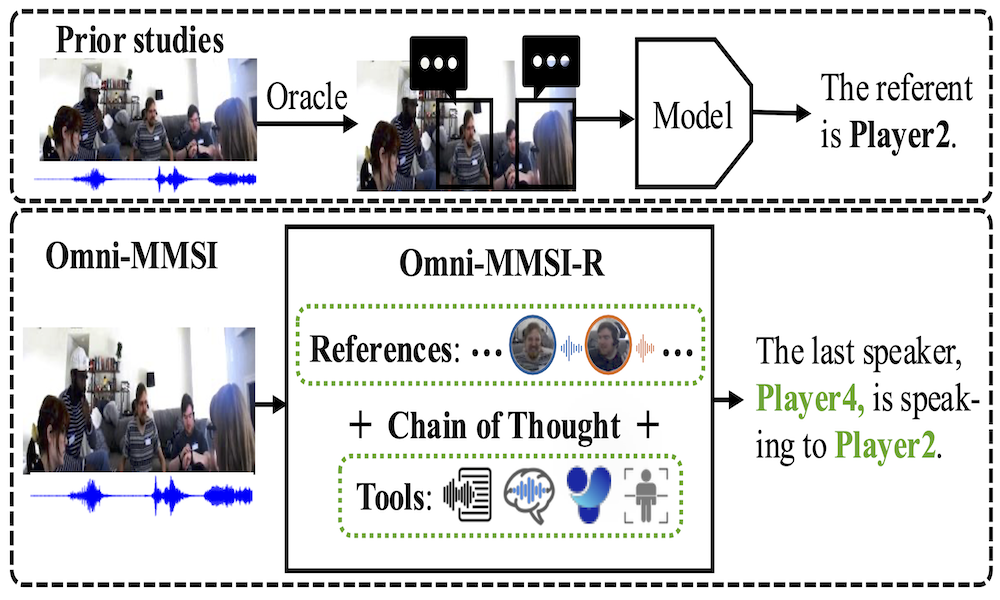
Omni-MMSI: Toward Identity-attributed Social Interaction Understanding
Xinpeng Li, Bolin Lai, Hardy Chen, Shijian Deng, Cihang Xie, Yuyin Zhou, James Matthew Rehg, Yapeng Tian
CVPR'26: IEEE/CVF Conference on Computer Vision and Pattern Recognition.

Object-WIPER: Training-Free Object and Associated Effect Removal in Videos
Saksham Singh Kushwaha, Sayan Nag, Yapeng Tian, Kuldeep Kulkarni
CVPR'26: IEEE/CVF Conference on Computer Vision and Pattern Recognition.

Hear What You See: Video-to-Audio Generation with Diffusion Transformer and Semantic-Temporal Alignment-Ranked Direct Preference Optimization
Kai Wang, Tao Zhou, jiayi lei, Jing Wang, Jinman Zhao, Weiguo Pian, Yuan Cheng, Yapeng Tian, Peng Gao, Bin Fu, Yihao Liu, Dimitrios Hatzinakos, Yuewen Cao
CVPR'26: IEEE/CVF Conference on Computer Vision and Pattern Recognition.

emoji_eventsHow Much Future Helps? A Controlled Study of Future-Privileged Supervision for Causal Egocentric Gaze Estimation (Best Paper Award)
Jia Li, Wenjie Zhao, Fnu Atisri, Sanskriti Aripineni, Shijian Deng, Jon E. Froehlich, Yuhang Zhao, Yapeng Tian
CVPRW'26: CVPR GAZE Workshop.
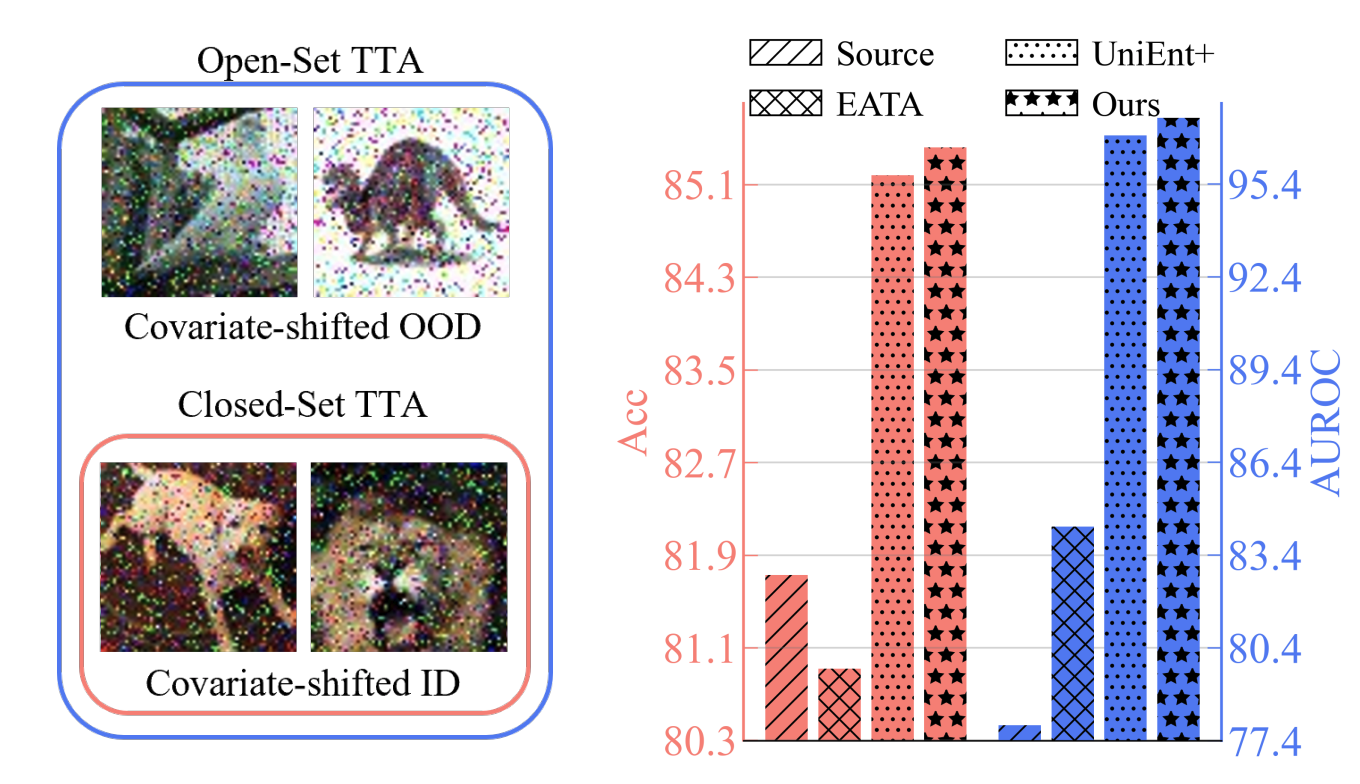
Mitigating the ID–OOD Tradeoff in Open-Set Test-Time Adaptation
Wenjie Zhao, Jia Li, Xin Dong, Yapeng Tian, Yu Xiang, Yunhui Guo
CVPR Findings'26: IEEE/CVF Conference on Computer Vision and Pattern Recognition.
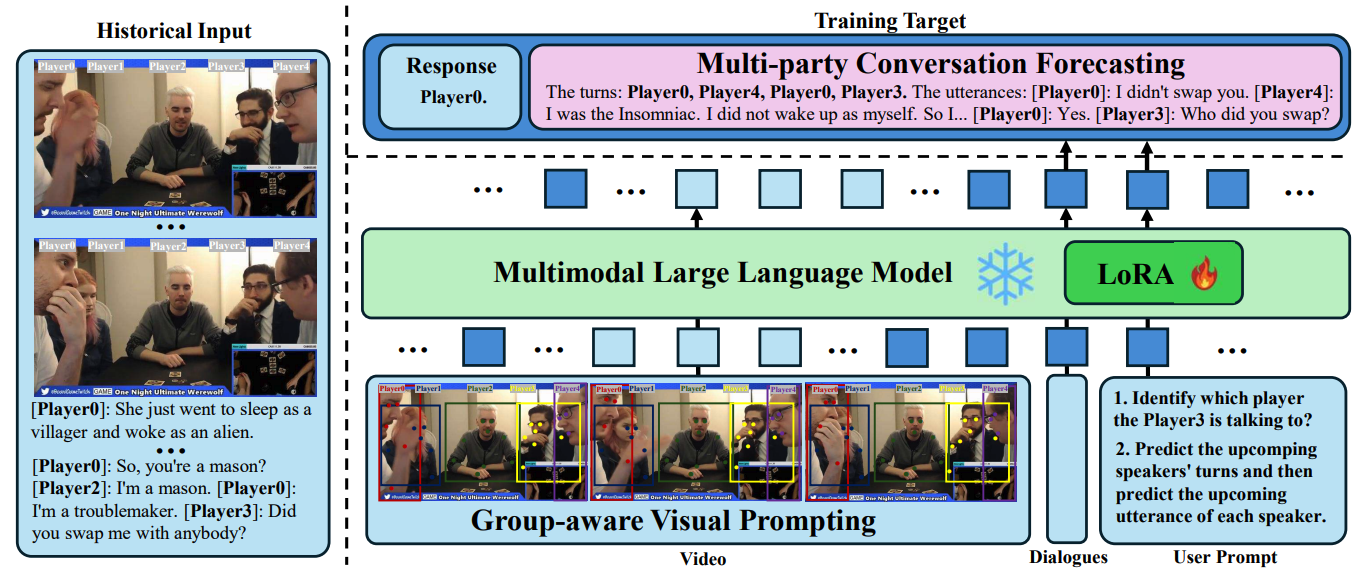
Towards Online Multi-Modal Social Interaction Understanding
Xinpeng Li, Shijian Deng, Bolin Lai, Weiguo Pian, James M. Rehg, Yapeng Tian
TMLR'26: Transactions on Machine Learning Research.
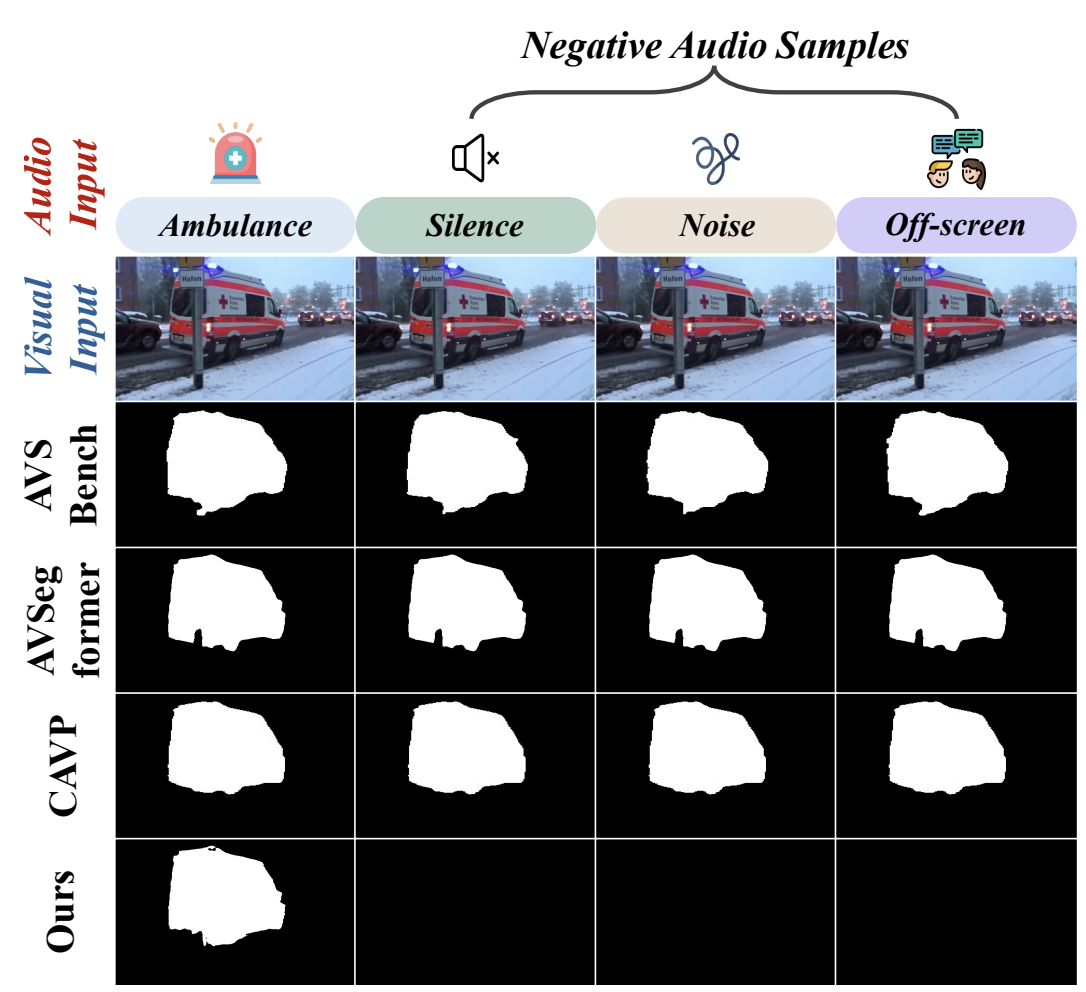
Do Audio-Visual Segmentation Models Truly Segment Sounding Objects?
Jia Li, Wenjie Zhao, Ziru Huang, Yunhui Guo, Yapeng Tian
AAAI'26: Annual AAAI Conference on Artificial Intelligence.

Toward Gaze Target Detection of Young Autistic Children
Shijian Deng, Erin E. Kosloski, Siva Sai Nagender Vasireddy, Jia Li, Randi Sierra Sherwood, Feroz Mohamed Hatha, Siddhi Patel, Pamela R Rollins, Yapeng Tian
AAAI'26 Oral: AAAI Conference on Artificial Intelligence (Social Impact Track).

Touch with Meaning: A Contextual Analysis of Social Touch
Ayush Bhardwaj, Ashish Pratap, Abbas Khawaja, Yapeng Tian, Uison Ju, Dajin Lee, Seungmoon Choi, and Jin Ryong Kim
CHI'26: ACM CHI Conference on Human Factors in Computing Systems.
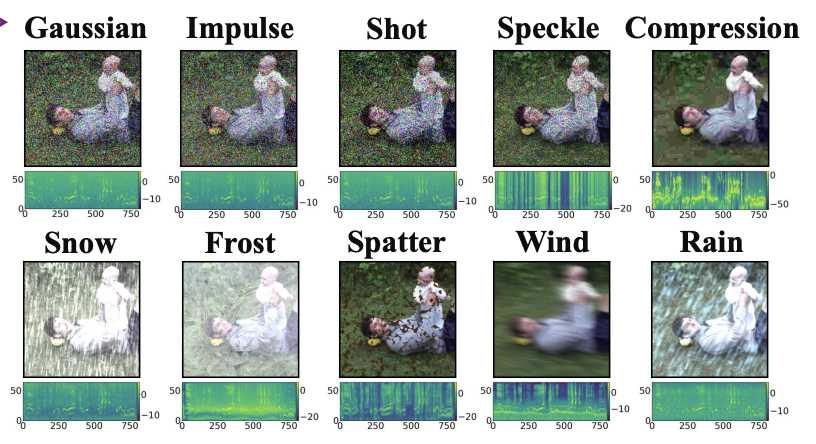
AVROBUSTBENCH: Benchmarking the Robustness of Audio-Visual Recognition Models at Test-Time
Sarthak Kumar Maharana, Saksham Singh Kushwaha, Baoming Zhang, Adrian Rodriguez, Songtao Wei, Yapeng Tian, Yunhui Guo
NeurIPS'25: Conference on Neural Information Processing Systems (D&B Track).
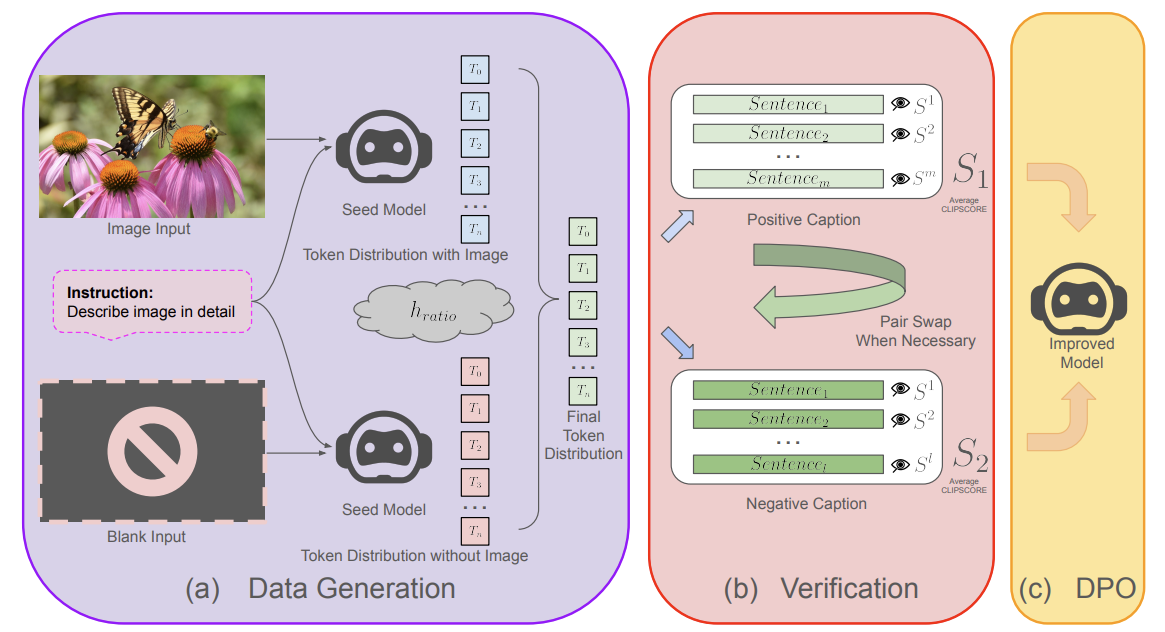
Efficient Self-Improvement in Multimodal Large Language Models: A Model-Level Judge-Free Approach
Shijian Deng, Wentian Zhao, Yu-Jhe Li, Kun Wan, Daniel Miranda, Ajinkya Kale, Yapeng Tian
COLM'25: Second Conference on Language Modeling.

Self-Improvement in Multimodal Large Language Models: A Survey
Shijian Deng, Kai Wang, Tianyu Yang, Harsh Singh, Yapeng Tian
EMNLP'25 Findings: Conference on Empirical Methods in Natural Language Processing.
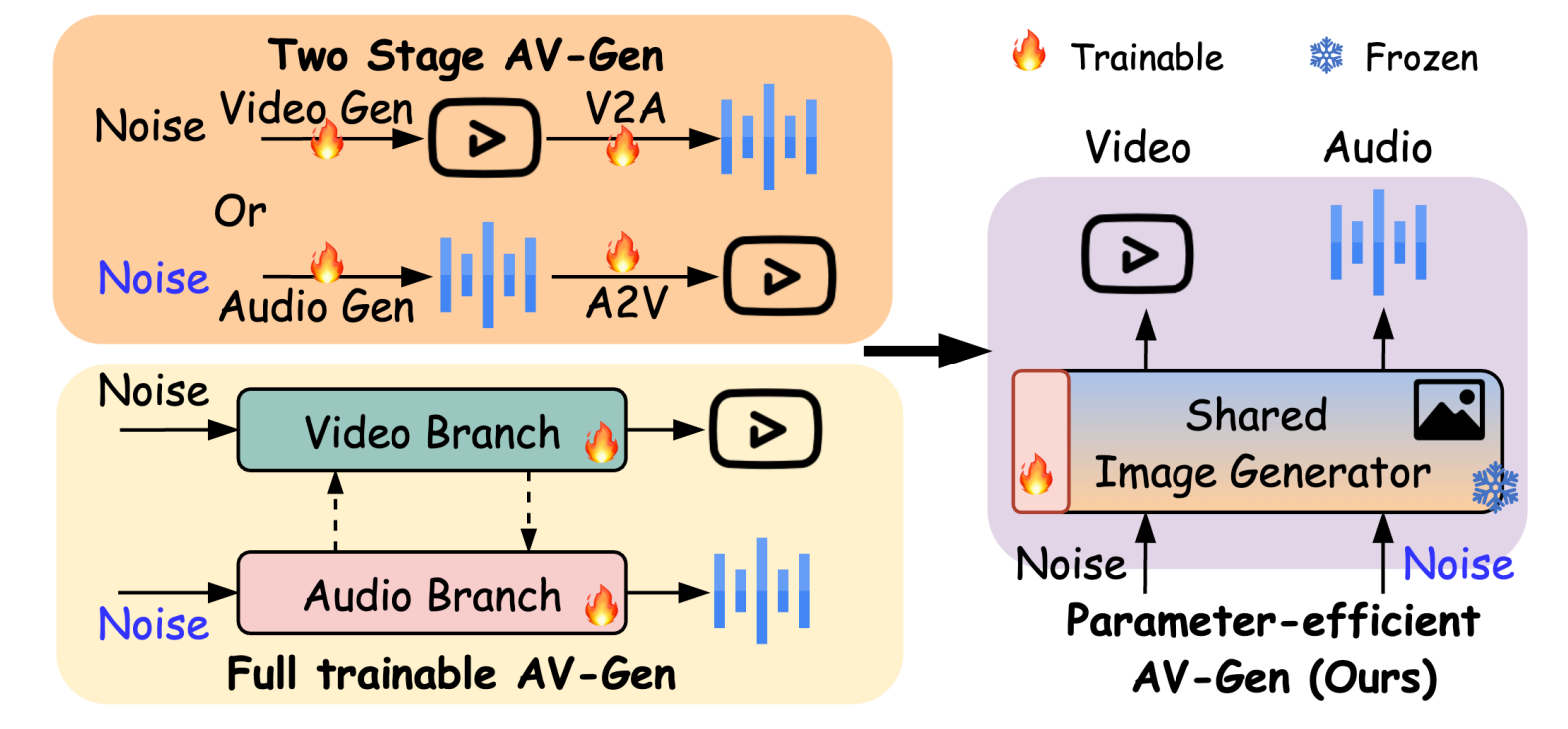
AV-DiT: Efficient Audio-Visual Diffusion Transformer for Joint Audio and Video Generation
Kai Wang, Shijian Deng, Jing Shi, Dimitrios Hatzinakos, Yapeng Tian
ACM MM'25: ACM International Conference on Multimedia.

High-Quality Sound Separation Across Diverse Categories via Visually-Guided Generative Modeling
Chao Huang, Susan Liang, Yapeng Tian, Anurag Kumar, Chenliang Xu
IJCV'25: International Journal of Computer Vision.

VRSight: An AI-Driven Scene Description System to Improve Virtual Reality Accessibility for Blind People
Daniel Killough, Justin Feng, Zheng Xue Ching, Daniel Wang, Rithvik Dyava, Yapeng Tian, Yuhang Zhao
UIST'25: ACM Symposium on User Interface Software and Technology.

AROMA: Mixed-Initiative AI Assistance for Non-Visual Cooking by Grounding Multi-modal Information Between Reality and Videos
Zheng Ning, Leyang Li, Daniel Killough, JooYoung Seo, Patrick Carrington, Yapeng Tian, Yuhang Zhao, Franklin Mingzhe Li, Toby Jia-Jun Li
UIST'25: ACM Symposium on User Interface Software and Technology.

TP-Blend: Textual-Prompt Attention Pairing for Precise Object-Style Blending in Diffusion Models
Xin Jin, Yichuan Zhong, Yapeng Tian
TMLR'25: Transactions on Machine Learning Research.

Prompt Image to Watch and Hear: Multimodal Prompting for Parameter-Efficient Audio-Visual Learning
Kai Wang, Shentong Mo, Yapeng Tian, Dimitrios Hatzinakos
BMVC'25: The British Machine Vision Conference (BMVC).
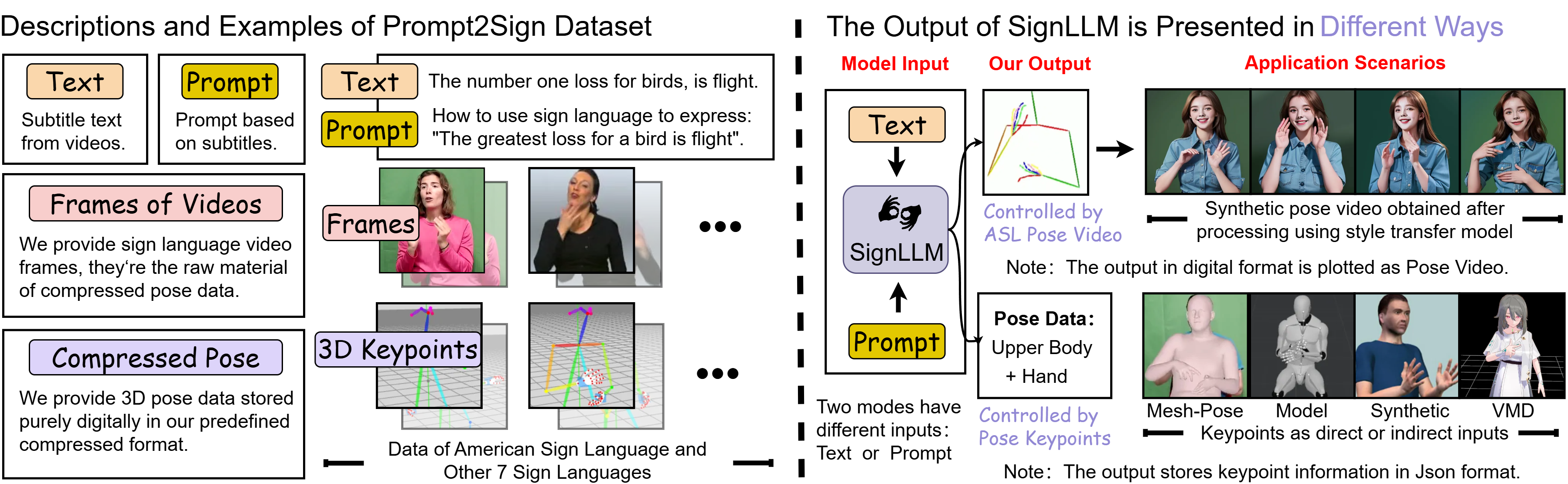
Signllm: Sign language production large language models
Sen Fang, Chen Chen, Lei Wang, Ce Zheng, Chunyu Sui, Yapeng Tian
ICCVW'25: IEEE/CVF International Conference on Computer Vision CV4A11y Workshop.

Introduction to the First Workshop on Vision Foundation Models and Generative AI for Accessibility
Yapeng Tian, Yuhang Zhao, Jon E. Froehlich, Chu Li, Yuheng Wu
ICCVW'25: IEEE/CVF International Conference on Computer Vision CV4A11y Workshop.

ZFusion: Efficient Deep Compositional Zero-shot Learning for Blind Image Super-Resolution with Generative Diffusion Prior
Alireza Esmaeilzehi, Hossein Zaredar, Yapeng Tian, Laleh Seyyed-Kalantari
ICCV'25: IEEE/CVF International Conference on Computer Vision.

PRVQL: Progressive Knowledge-guided Refinement for Robust Egocentric Visual Query Localization
Bing Fan, Yunhe Feng, Yapeng Tian, Yuewei Lin, Yan Huang, Heng Fan
ICCV'25: IEEE/CVF International Conference on Computer Vision.
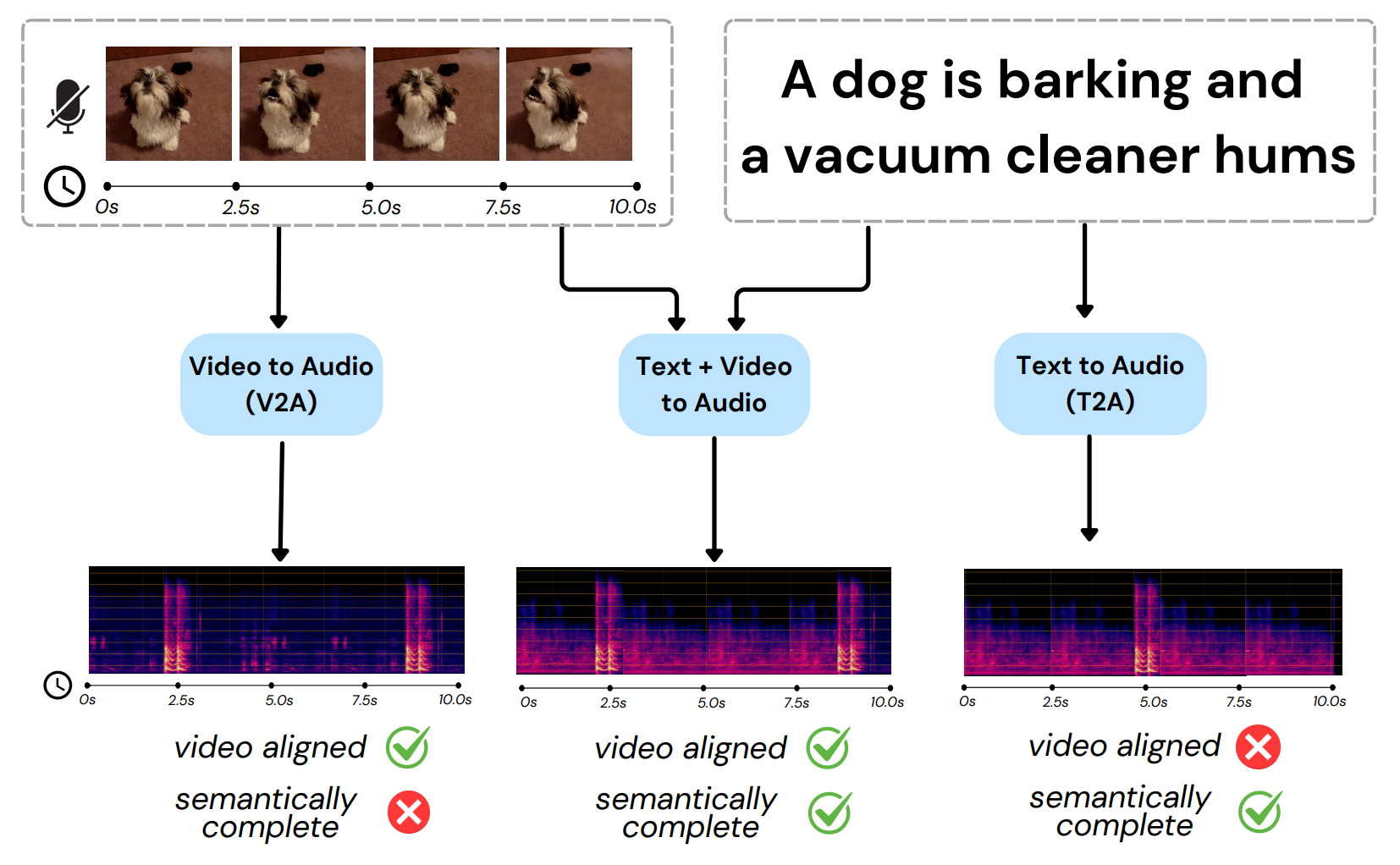
VinTAGe: Joint Video and Text Conditioning for Holistic Audio Generation
Saksham Singh Kushwaha, Yapeng Tian
CVPR'25: IEEE/CVF Conference on Computer Vision and Pattern Recognition.

Motion-Grounded Video Reasoning: Understanding and Perceiving Motion at Pixel Level
Andong Deng, Tongjia Chen, Shoubin Yu, Taojiannan Yang, Lincoln Spencer, Yapeng Tian, Ajmal Saeed Mian, Mohit Bansal, Chen Chen
CVPR'25: IEEE/CVF Conference on Computer Vision and Pattern Recognition.
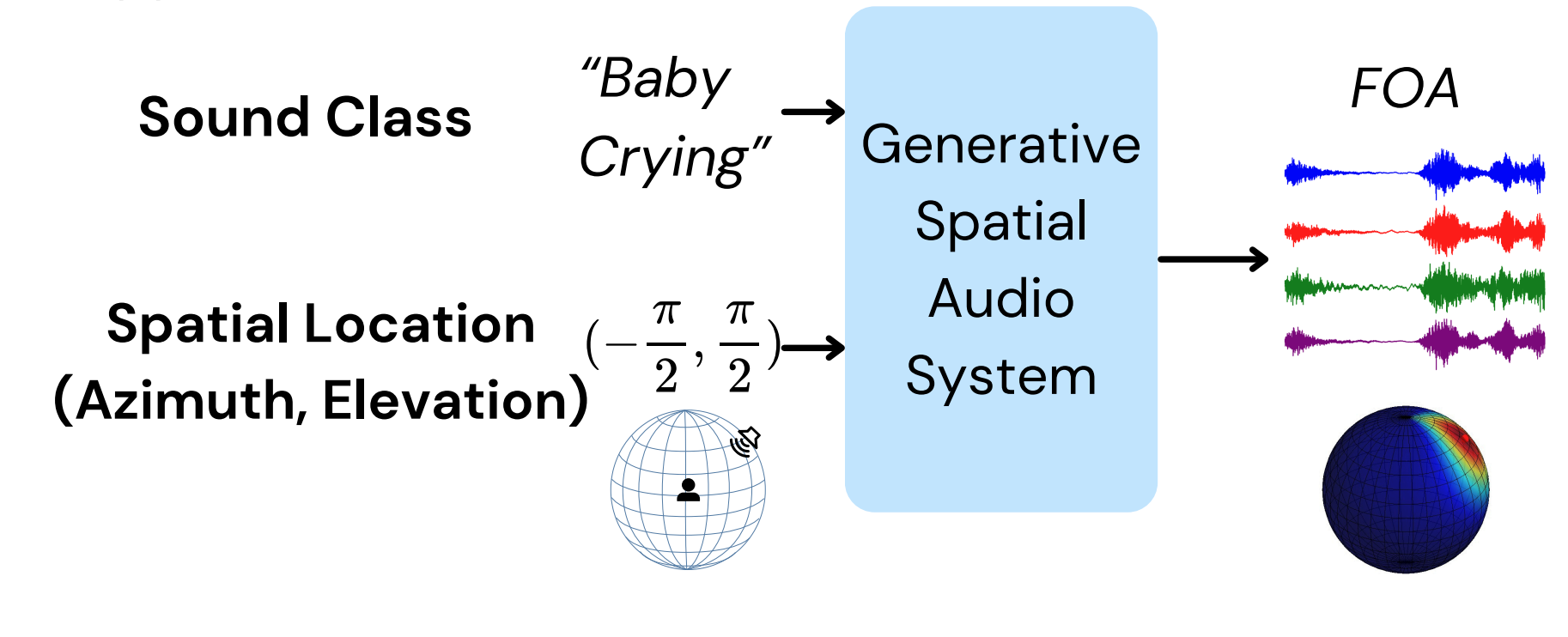
Diff-SAGe: End-to-End Spatial Audio Generation Using Diffusion Models
Saksham Singh Kushwaha, Jianbo Ma, Mark R. P. Thomas, Yapeng Tian, and Avery Bruni
ICASSP'25: IEEE International Conference on Acoustics, Speech, and Signal Processing.

CLIPErase: Efficient Unlearning of Visual-Textual Associations in CLIP
Tianyu Yang, Lisen Dai, Zheyuan Liu, Xiangqi Wang, Meng Jiang, Yapeng Tian, Xiangliang Zhang
ACL'25 Main: Annual Meeting of the Association for Computational Linguistics.

MagicTalk: Implicit and Explicit Correlation Learning for Diffusion-based Emotional Talking Face Generation
Chenxu Zhang, Chao Wang, Jianfeng Zhang, Hongyi Xu, Guoxian Song, You Xie, Linjie Luo, Yapeng Tian, Jiashi Feng, Xiaohu Guo
CVM: Computational Visual Media Journal.

Demonstration of VRSight: AI-Driven Real-Time Descriptions to Enhance VR Accessibility for Blind People
Daniel Killough, Justin Feng, Rithvik Dyava, Zheng Xue Ching, Daniel Wang, Yapeng Tian, Yuhang Zhao
CHI EA'25: Extended Abstracts of the CHI Conference

Leveraging AI to Assess Social Attention in Young Autistic Children
Erin Kosloski, Shijian Deng, Siva S. N. Vasireddy, Randi S. Sherwood, Feroz M. Hatha, Jia Li, Siddhi Patel, Yapeng Tian, Pamela Rollins
SRCLD'25: Symposium on Research in Child Language Disorders.

SignDiff: Learning Diffusion Models for American Sign Language Production
Sen Fang, Chunyu Sui, Yanghao Zhou, Xuedong Zhang, Hongbin Zhong, Yapeng Tian, Chen Chen
FGW'25: International Conference on Automatic Face and Gesture Recognition Workshop.
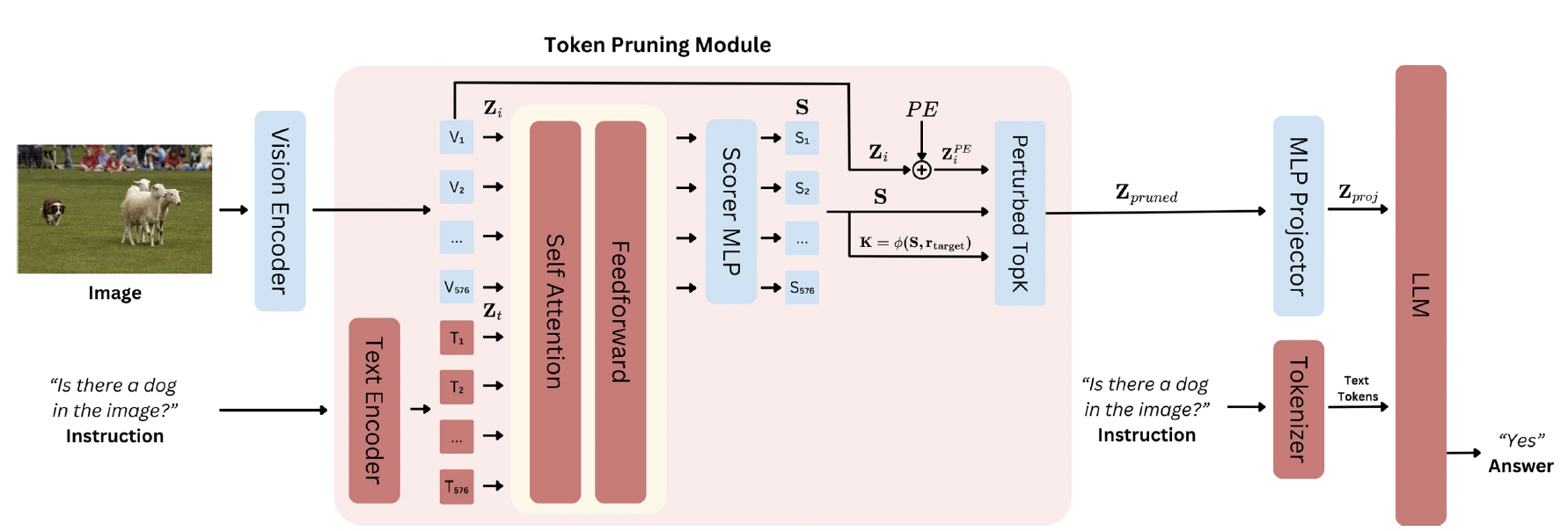
Language-Guided Adaptive Vision Token Pruning for Efficient Multimodal Large Language Models
Omer Faruk Deniz, Tarik Arici, Fatemeh Sheikholeslami, Burak Gozluklu, Ameni Trabelsi, Suleiman Khan, Yapeng Tian, Latifur Khan
PAKDD'25 Oral: The Pacific-Asia Conference on Knowledge Discovery and Data Mining.

Joint Co-Speech Gesture and Expressive Talking Face Generation using Diffusion with Adapters
Steven Hogue, Chenxu Zhang, Yapeng Tian, Xiaohu Guo
WACV'25: IEEE/CVF Winter Conference on Applications of Computer Vision.

DiffIR: Efficient Diffusion Model for Image Restoration
Bin Xia, Yulun Zhang, Shiyin Wang, Yitong Wang, Xinglong Wu, Yapeng Tian, Wenming Yang, Radu Timotfe, Luc Van Gool
TPAMI'25: IEEE Transactions on Pattern Analysis and Machine Intelligence.
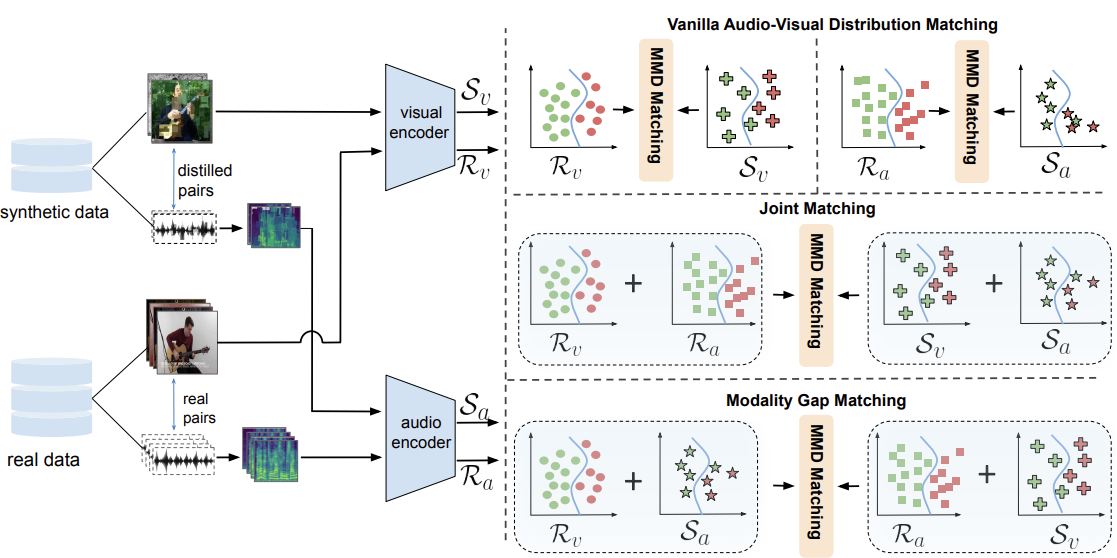
Audio-Visual Dataset Distillation
Saksham Singh Kushwaha, Siva Sai Nagender Vasireddy, Kai Wang, Yapeng Tian
TMLR'24: Transactions on Machine Learning Research
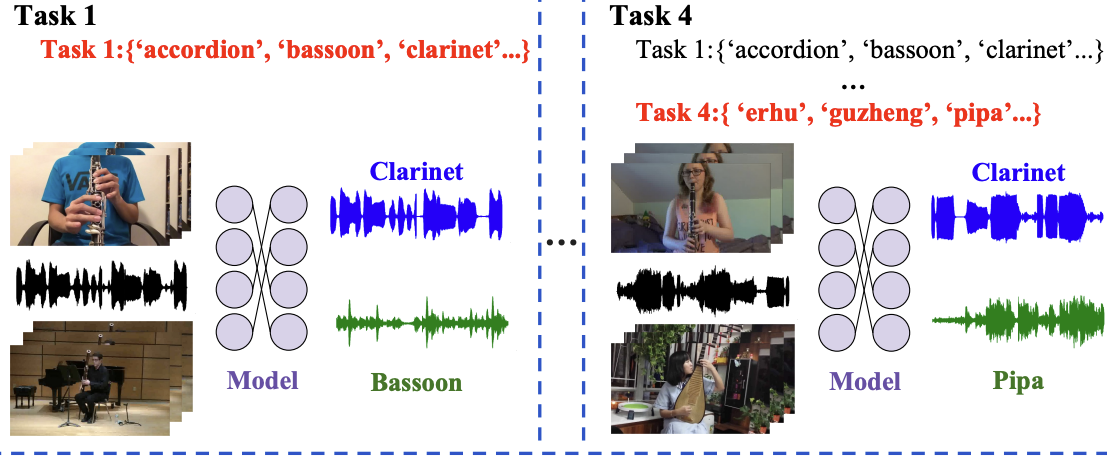
Continual Audio-Visual Sound Separation
Weiguo Pian, Yiyang Nan, Shijian Deng, Shentong Mo, Yunhui Guo, Yapeng Tian
NeurIPS'24: The Annual Conference on Neural Information Processing Systems
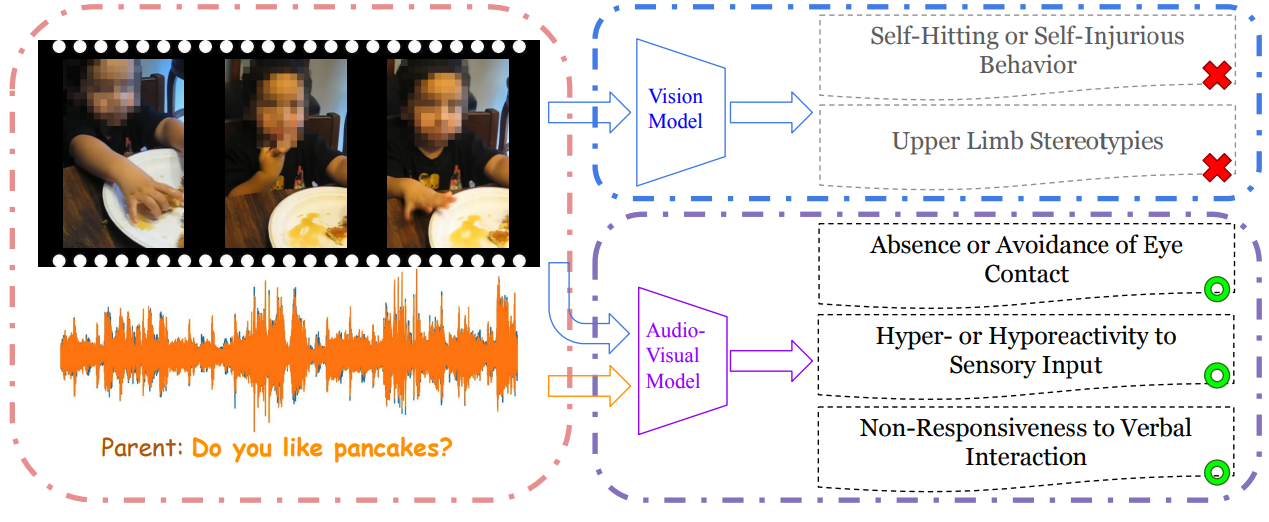
Hear Me, See Me, Understand Me: Audio-Visual Autism Behavior Recognition
Shijian Deng, Erin Kosloski, Siddhi Patel, Zeke A Barnett, Yiyang Nan, Alexander M Kaplan, Sisira Aarukapalli, William Doan, Matthew Wang, Harsh Singh, Rollins Pamela, Yapeng Tian
TMM'24: IEEE Transactions on Multimedia.
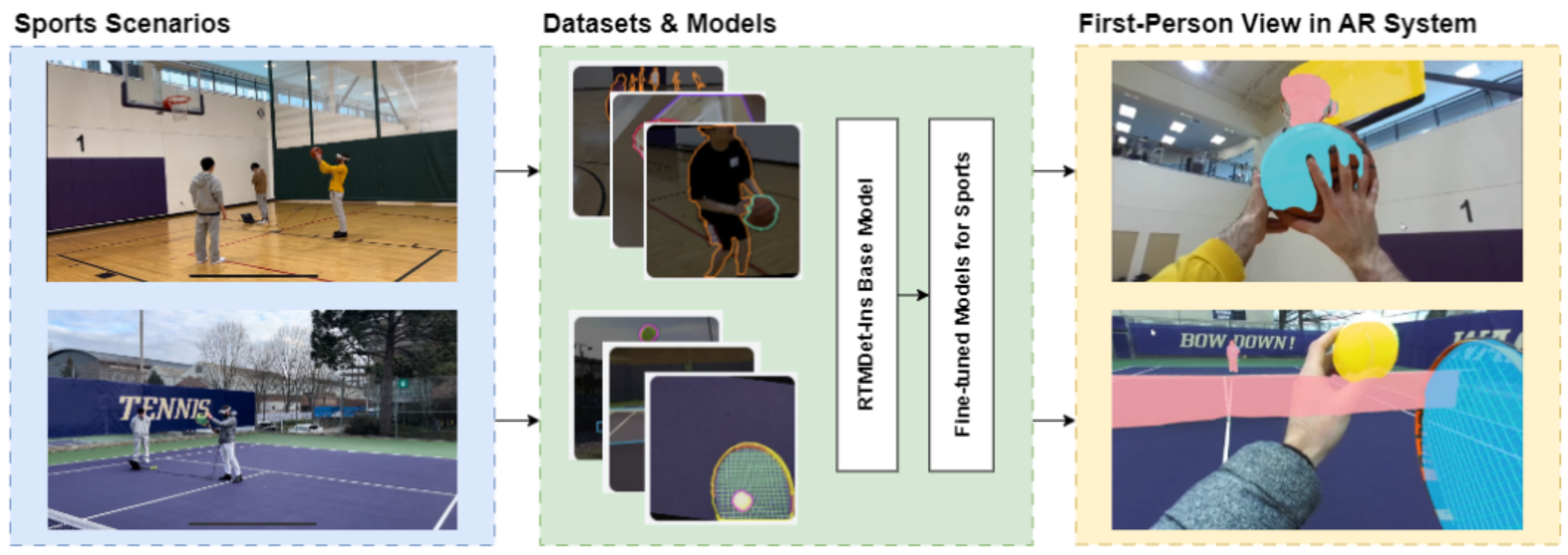
emoji_eventsTowards AI-Powered AR for Enhancing Sports Playability for People with Low Vision: An Exploration of ARSports (Best Paper Award)
Jaewook Lee, Yang Li, Dylan Bunarto, Eujean Lee, Olivia Wang, Adrian Rodriguez, Yuhang Zhao, Yapeng Tian, Jon E. Froehlich
ISMAR IDEATExR'24 : International Symposium on Mixed and Augmented Reality Workshop.

emoji_events CookAR: Affordance Augmentations in Wearable AR to Support Kitchen Tool Interactions for People with Low Vision (Belonging & Inclusion Best Paper Award)
Jaewook Lee, Andrew D. Tjahjadi, Jiho Kim, Junpu Yu, Minji Park, Jiawen Zhang, Jon E. Froehlich, Yapeng Tian, Yuhang Zhao
UIST'24: ACM Symposium on User Interface Software and Technology.
emoji_events DAVIS: High-Quality Audio-Visual Separation with Generative Diffusion Models
(Best Paper Honorable Mention)
Chao Huang, Susan Liang, Yapeng Tian, Anurag Kumar, Chenliang Xu
ACCV'24 Oral: Asian Conference on Computer Vision.

Language-Guided Joint Audio-Visual Editing Via One-Shot Adaptation
Susan Liang, Chao Huang, Yapeng Tian, Anurag Kumar, Chenliang Xu
ACCV'24: Asian Conference on Computer Vision.
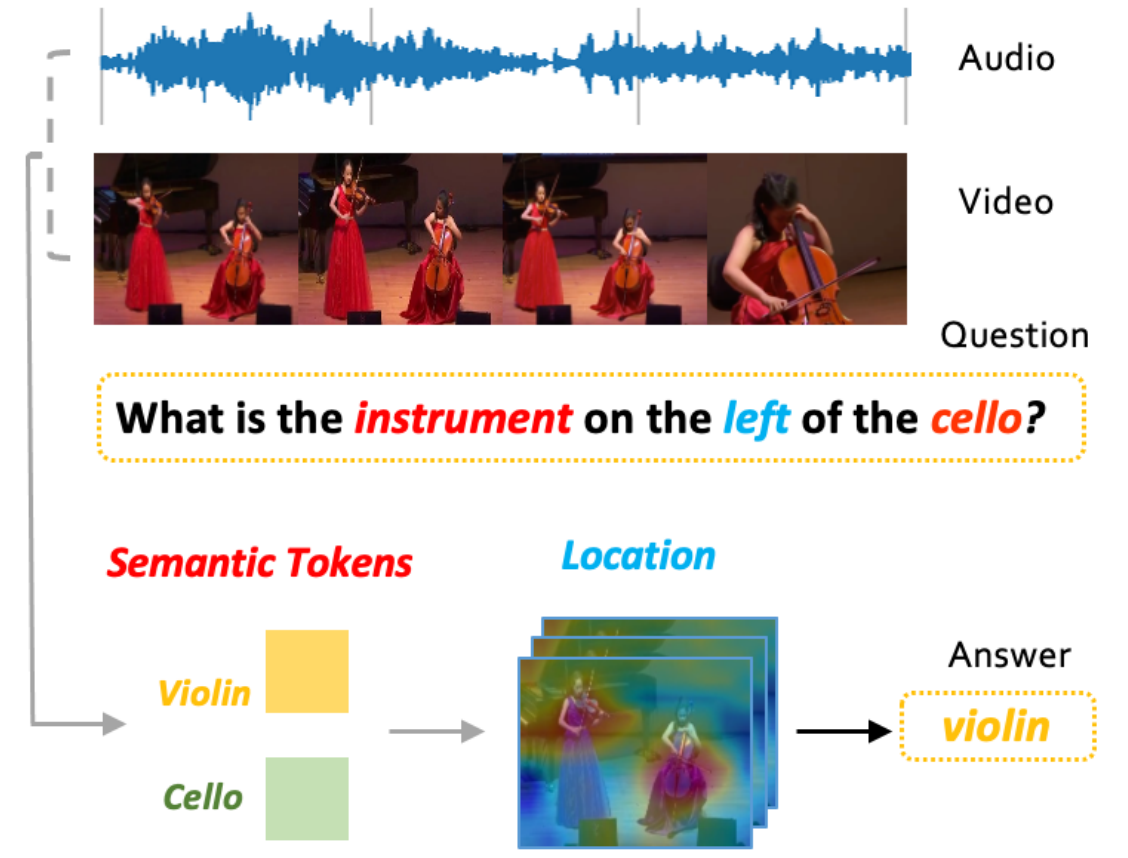
SaSR-Net: Source-Aware Semantic Representation Network for Enhancing Audio-Visual Question Answering
Tianyu Yang, Yiyang Nan, Lisen Dai, Zhenwen Liang, Yapeng Tian, Xiangliang Zhang
EMNLP'24: Empirical Methods in Natural Language Processing (Findings)
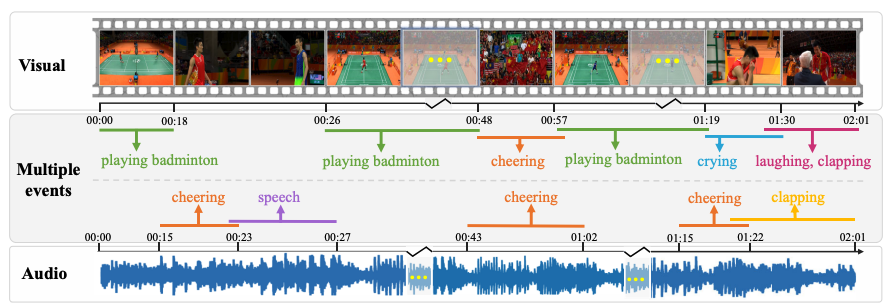
Towards Long Form Audio-visual Video Understanding
Wenxuan Hou, Guangyao Li, Yapeng Tian, Di Hu
TOMM'24: ACM Trans. on Multimedia Computing, Communications and App.
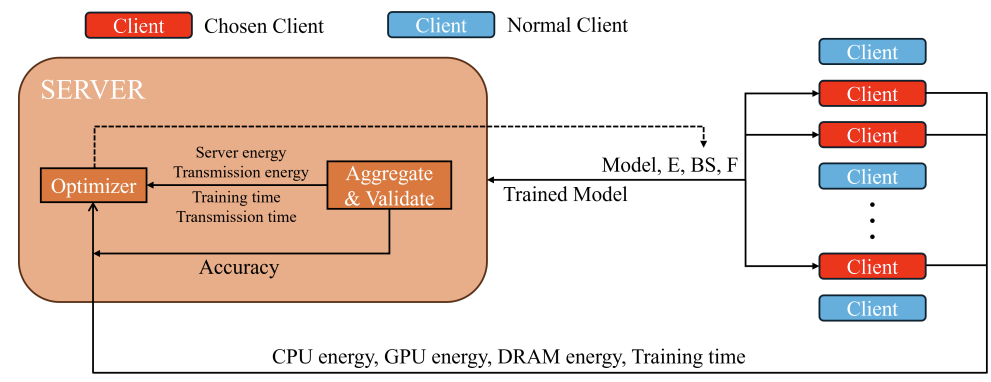
Benchmarking and Optimizing Federated Learning with Hardware-related Metrics
Kai Pan, Yapeng Tian, Yinhe Han, Yiming Gan
BMVC'24: British Machine Vision Conference

EgoVSR: Towards High-Quality Egocentric Video Super-Resolution
Yichen Chi, Junhao Gu, Jiamiao Zhang, Wenming Yang, Yapeng Tian
TCSVT'24: IEEE Transactions on Circuits and Systems for Video Technology.
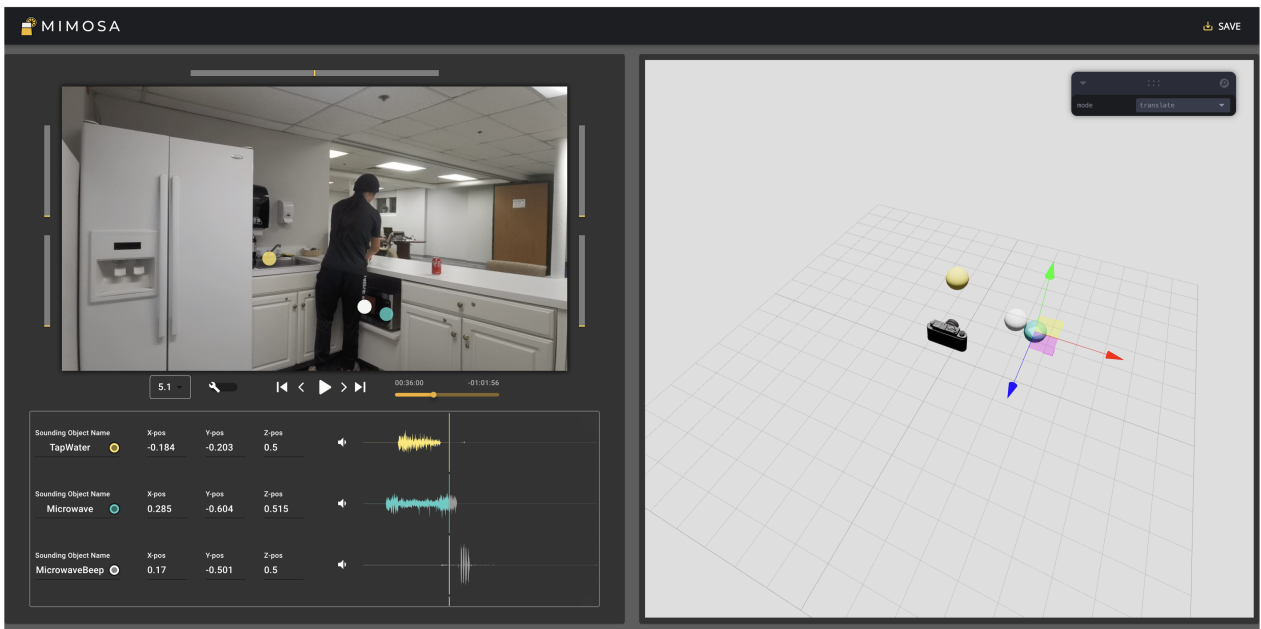
MIMOSA: Human-AI Co-Creation of Computational Spatial Audio Effects on Videos
Zheng Ning, Zheng Zhang, Jerrick Ban, Kaiwen Jiang, Ruohong Gan, Yapeng Tian, Toby Jia-Jun Li
C&C'24: ACM Conference on Creativity & Cognition.
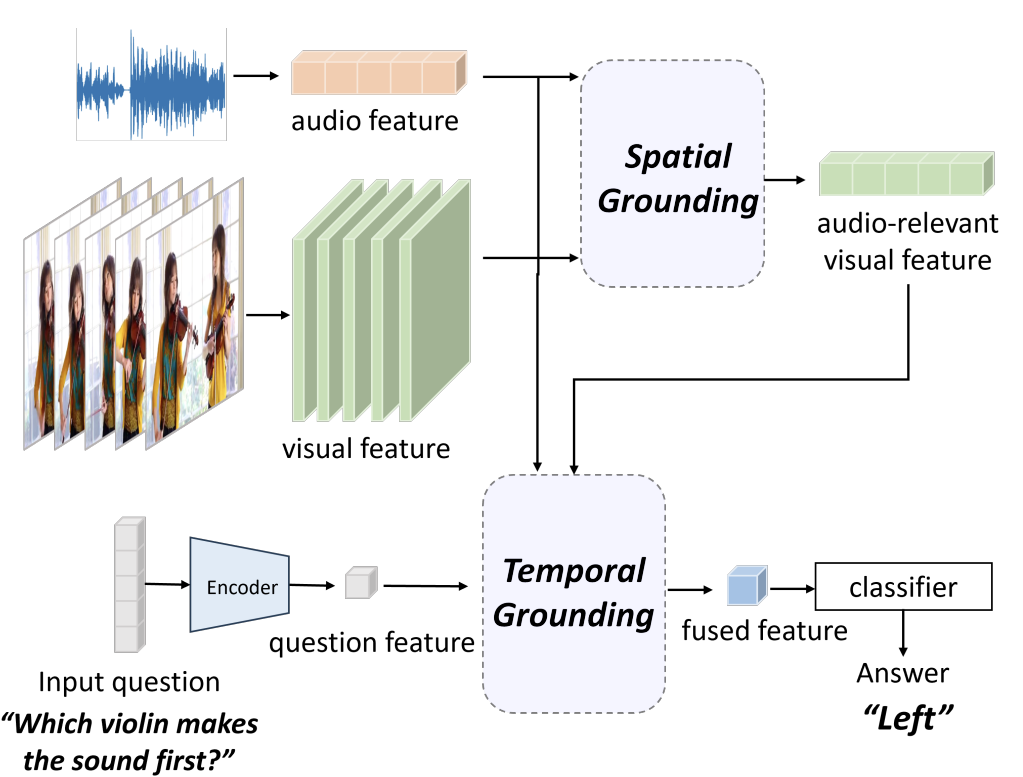
AV-Mamba: Cross-Modality Selective State Space Models for Audio-Visual Question Answering
Ziru Huang, Jia Li, Wenjie Zhao, Yunhui Guo, Yapeng Tian
CVPRW'24: CVPR Signt and Sound Workshop
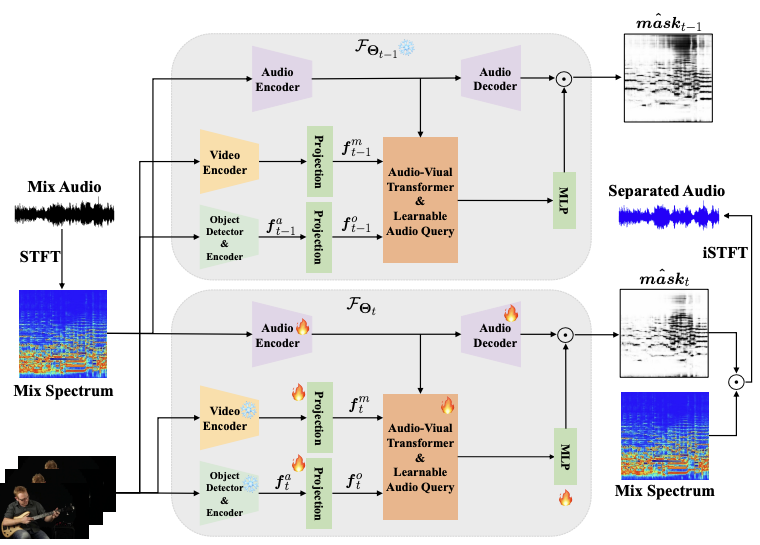
Learning Continual Audio-Visual Sound Separation Models
Weiguo Pian, Yiyang Nan, Shijian Deng, Shentong Mo, Yunhui Guo, Yapeng Tian
CVPRW'24: CVPR Signt and Sound Workshop
Audio-Visual Autism Behavior Recognition with MMLMs
Shijian Deng, Erin Kosloski, Siddhi Patel, Zeke A Barnett, Yiyang Nan, Alexander M Kaplan, Sisira Aarukapalli, William Doan, Matthew Wang, Harsh Singh, Rollins Pamela, Yapeng Tian
CVPRW'24: CVPR Signt and Sound Workshop
Dataset distillation for audio-visual datasets
Saksham Singh Kushwaha, Siva Sai Nagender Vasireddy, Kai Wang, Yapeng Tian
CVPRW'24: CVPR Signt and Sound Workshop
DiffTED: One-shot Audio-driven TED Talk Video Generation with Diffusion-based Co-speech Gestures
Steven Hogue, Chenxu Zhang, Hamza Daruger, Yapeng Tian, Xiaohu Guo
CVPRW'24: CVPR HuMoGen Workshop
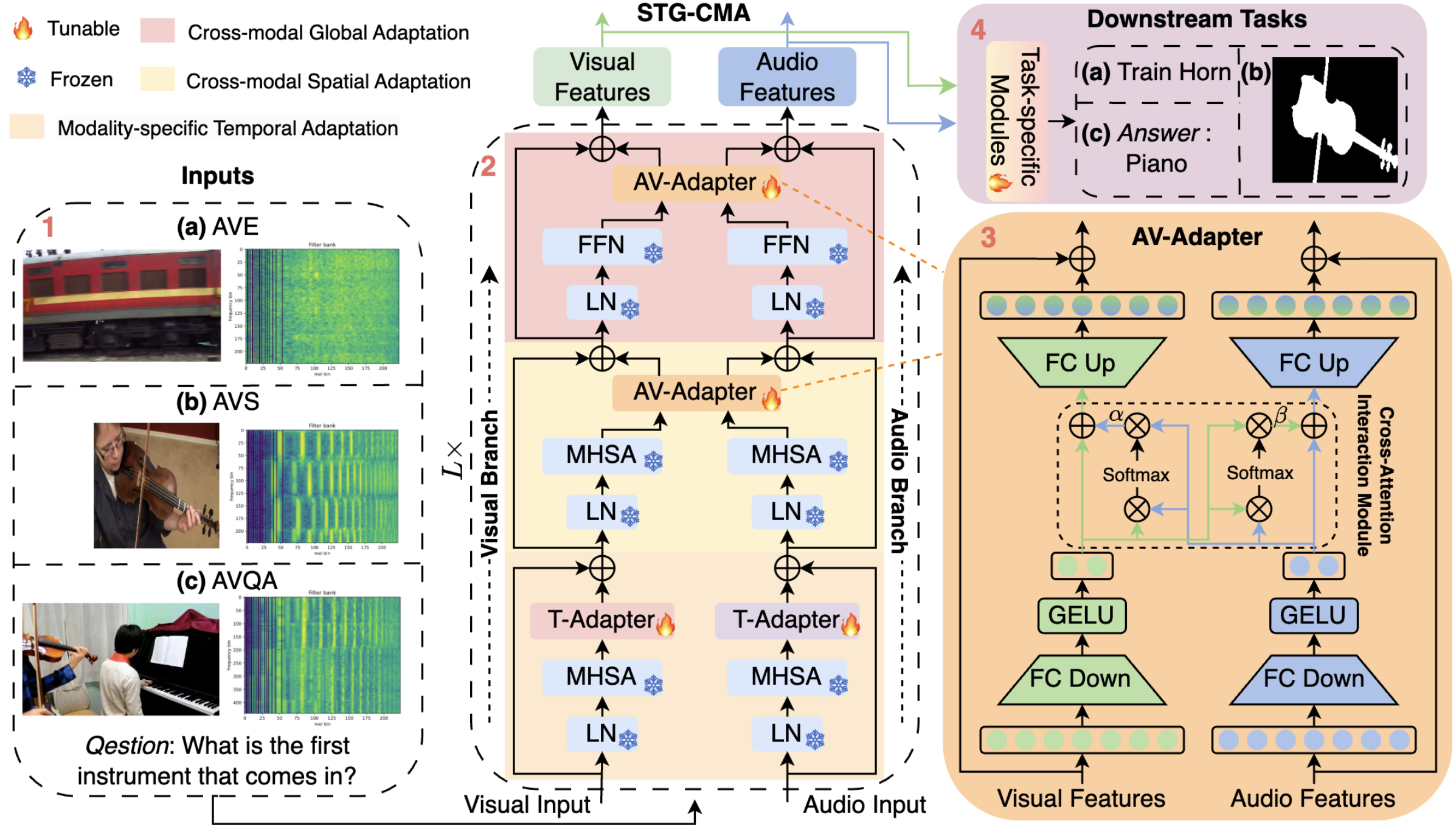
Towards Efficient Audio-Visual Learners via Empowering Pre-trained Vision Transformers with Cross-Modal Adaptation
Kai Wang, Yapeng Tian, Dimitrios Hatzinakos
CVPRW'24: CVPR Multimodal Foundation Models Workshop
MA-AVT: Modality Alignment for Parameter-Efficient Audio-Visual Transformers
Tanvir Mahmud, Shentong Mo, Yapeng Tian, Diana Marculescu
CVPRW'24: CVPR Efficient Deep Learning for Computer Vision Workshop
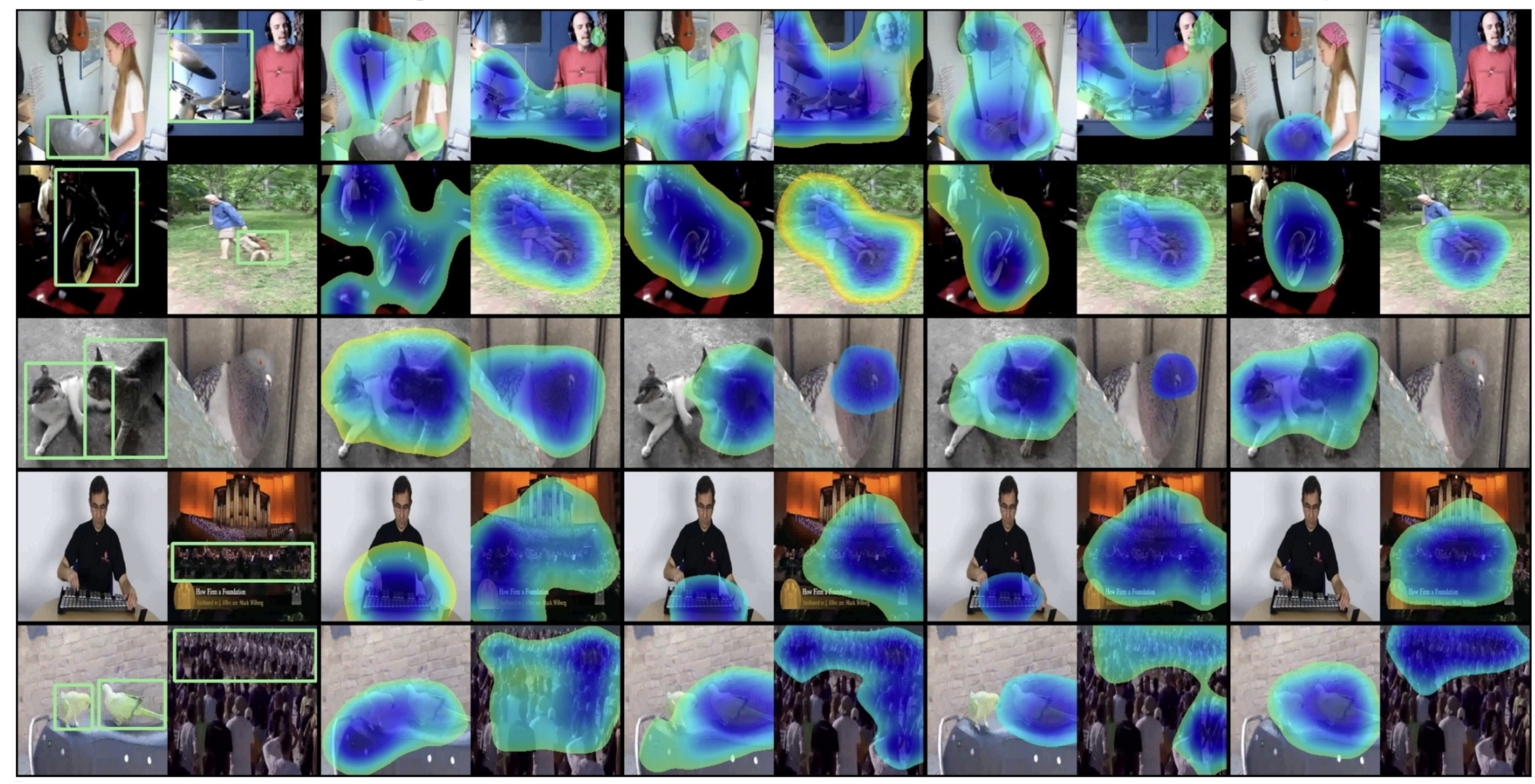
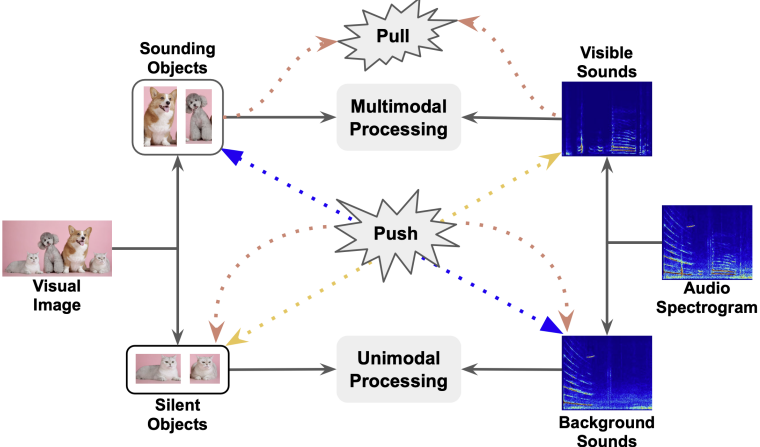
T-VSL: Text-Guided Visual Sound Source Localization in Mixtures
Tanvir Mahmud, Yapeng Tian, Diana Marculescu
CVPR'24: IEEE/CVF Conference on Computer Vision and Pattern Recognition

OSCaR: Object State Captioning and State Change Representation
Nguyen Nguyen, Jing Bi, Ali Vosoughi, Yapeng Tian, Pooyan Fazli, Chenliang Xu
NAACL'24: The North American Chapter of the Association for Computational Linguistics (Findings)
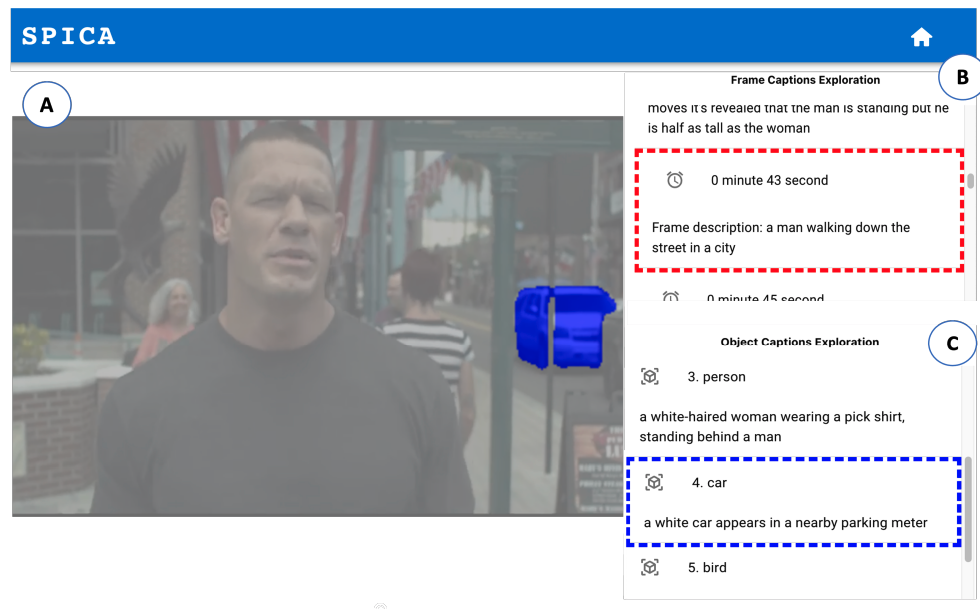
SPICA: Interactive Video Content Exploration through Augmented Audio Descriptions for Blind or Low-Vision Viewers
Zheng Ning, Brianna Wimer, Kaiwen Jiang, Keyi Chen, Jerrick Ban, Yapeng Tian, Yuhang Zhao, Toby Li
CHI'24: The ACM Conference on Human Factors in Computing Systems.
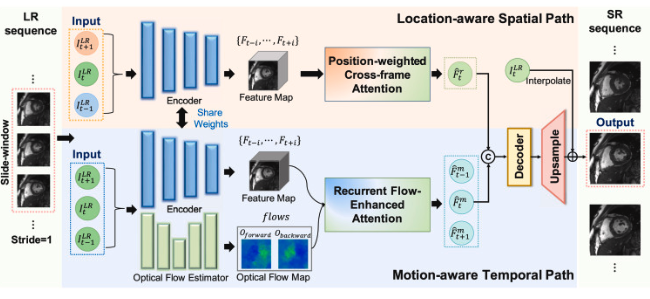
STADNet: Spatial-Temporal Attention-Guided Dual-Path Network for cardiac cine MRI super-resolution
Jun Lyu, Shuo Wang, Yapeng Tian, Jing Zou, Shunjie Dong, Chengyan Wang, Angelica I Aviles-Rivero, Jing Qin
MIA'24: Medical Image Analysis

Unveiling cross modality bias in visual question answering: A causal view with possible worlds vqa
Ali Vosoughi‡, Shijian Deng‡, Songyang Zhang, Yapeng Tian, Chenliang Xu, Jiebo Luo
TMM'24: IEEE Transactions on Multimedia
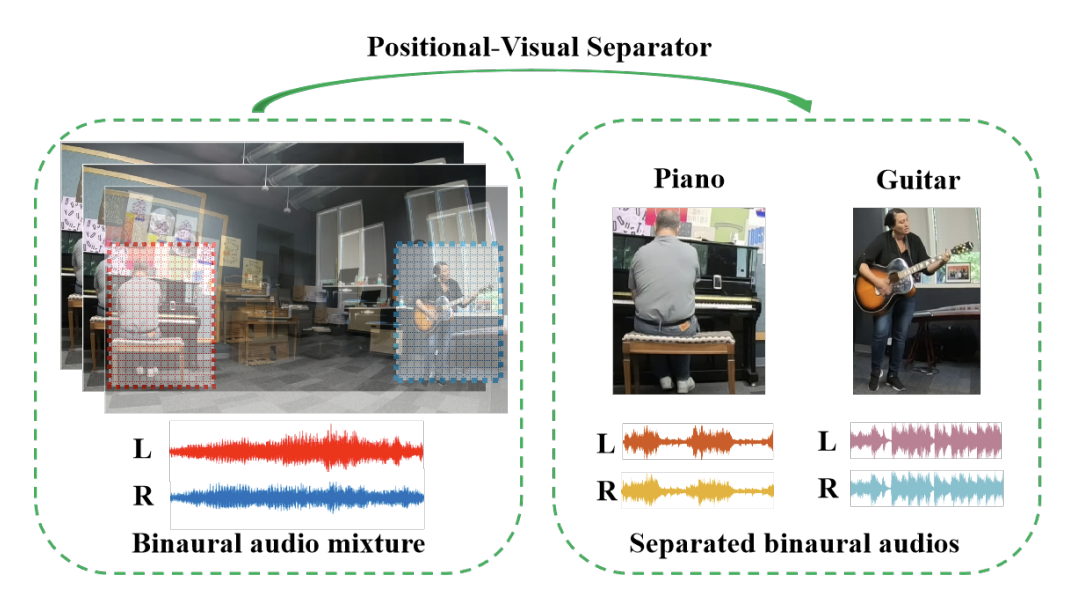
LAVSS: Location-Guided Audio-Visual Spatial Audio Separation
Yuxin Ye, Wenming Yang, Yapeng Tian
WACV'24: Winter Conference on Applications of Computer Vision.
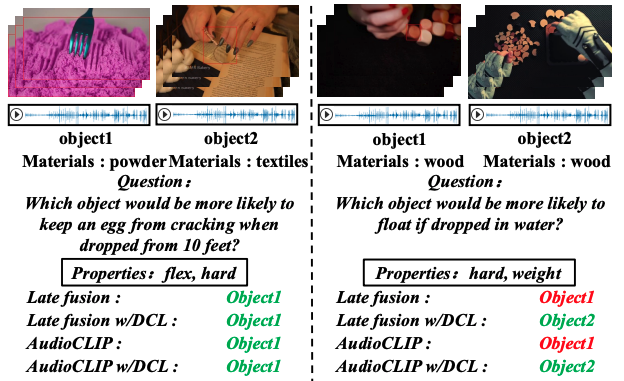
Disentangled counterfactual learning for physical audiovisual commonsense reasoning
Changsheng Lv, Shuai Zhang, Yapeng Tian, Mengshi Qi, Huadong Ma
NeurIPS'23: The Annual Conference on Neural Information Processing Systems.
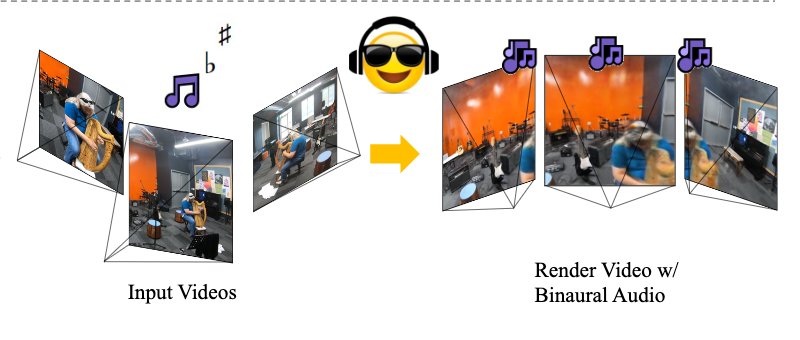
AV-NeRF: Learning Neural Fields for Real-World Audio-Visual Scene Synthesis
Susan Liang, Chao Huang, Yapeng Tian, Anurag Kumar, Chenliang Xu
NeurIPS'23: The Annual Conference on Neural Information Processing Systems.
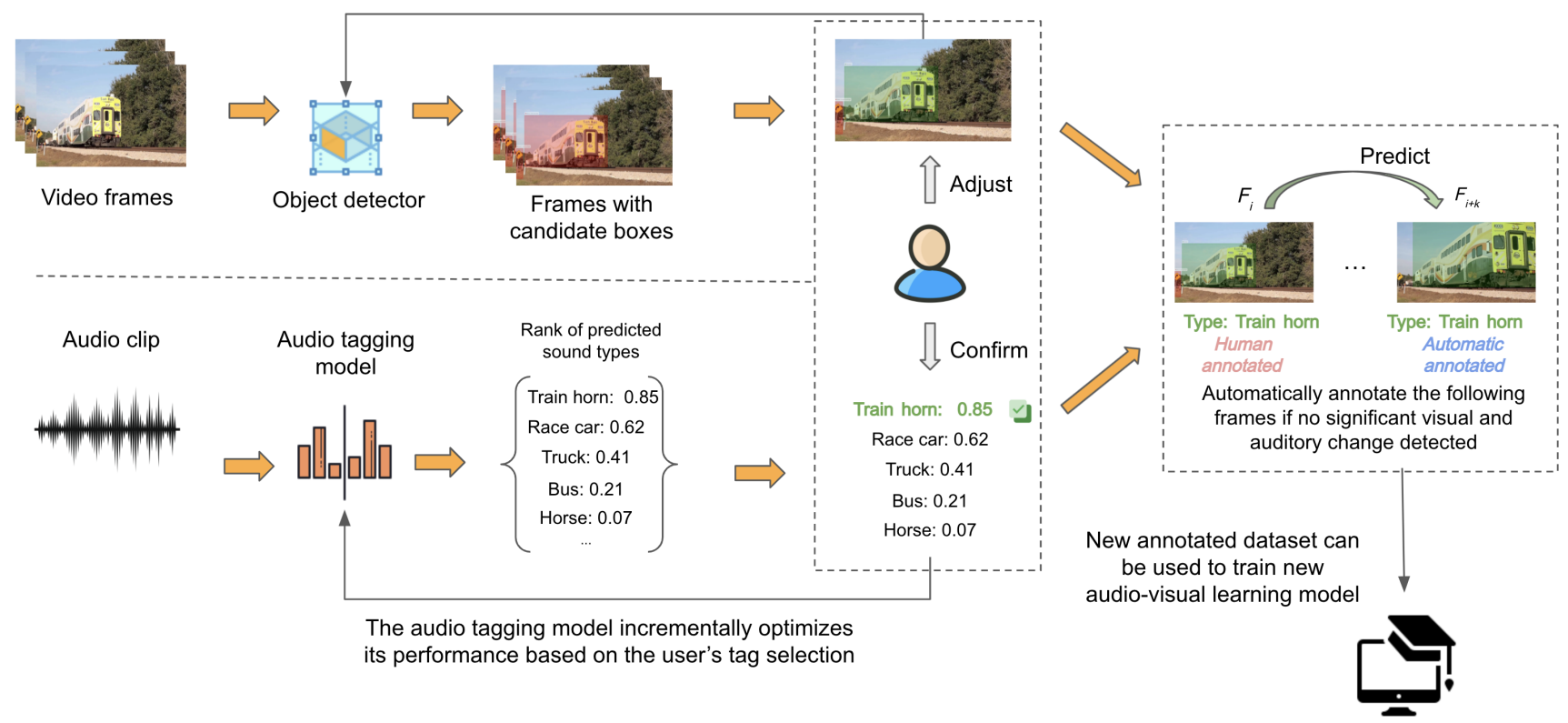
PEANUT: A Human-AI Collaborative Tool for Annotating Audio-Visual Data
Zheng Zhang‡, Zheng Ning‡, Chenliang Xu Yapeng Tian, Toby Jia-Jun Li
UIST'23: ACM Symposium on User Interface Software and Technology.
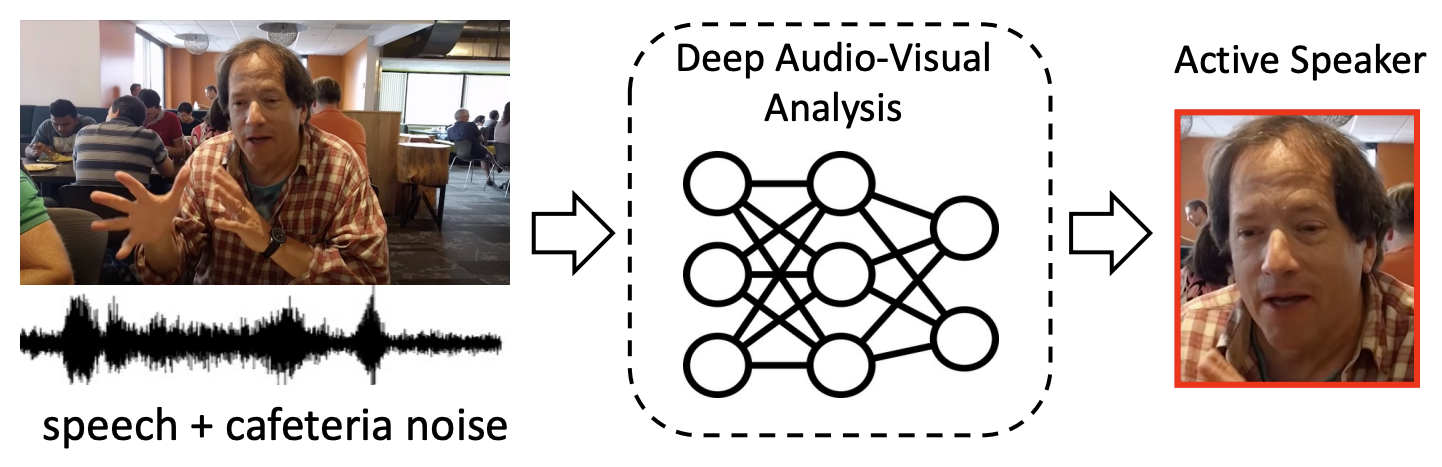
Towards Robust Active Speaker Detection
Siva Sai Nagender Vasireddy, Chenxu Zhang, Xiaohu Guo, Yapeng Tian
ICCVW'23: ICCV AV4D Workshop .
Position-Aware Audio-Visual Separation for Spatial Audio
Yuxin Ye, Wenming Yang, Yapeng Tian
ICCVW'23: ICCV AV4D Workshop .
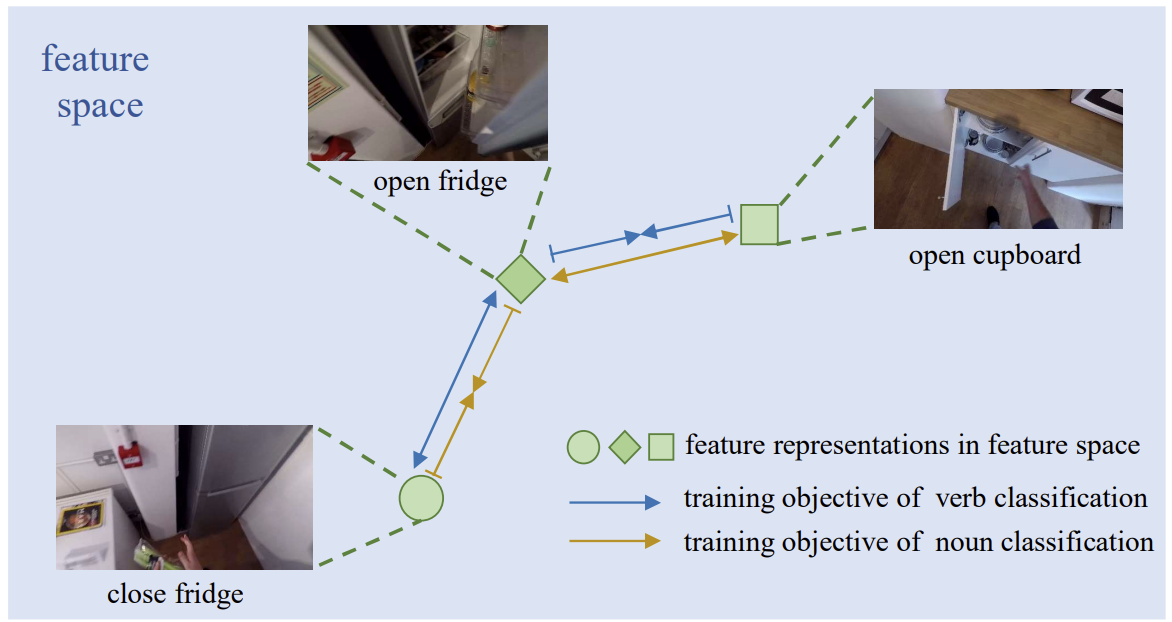
Towards Better Egocentric Action Understanding in a Multi-Input Multi-Output View
Wenxuan Hou, Ruoxuan Feng, Yixin Xu, Yapeng Tian, Di Hu
ICCVW'23: ICCV AV4D Workshop .
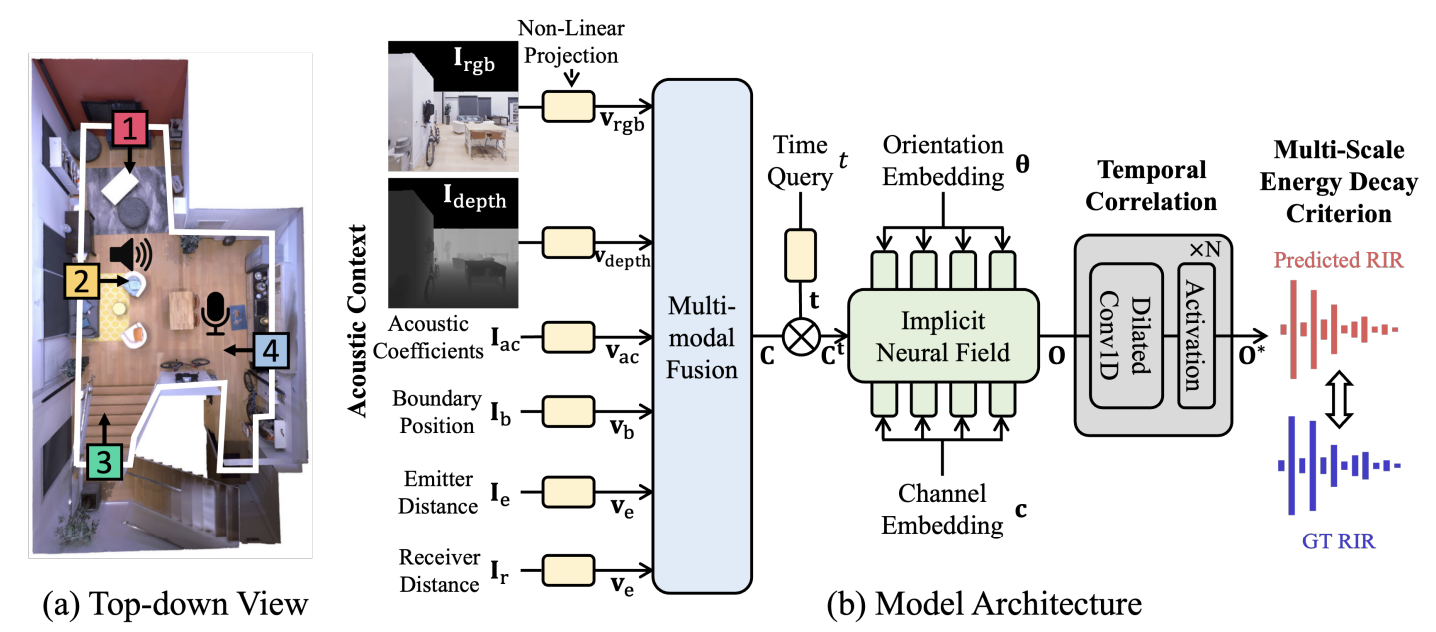
Neural Acoustic Context Field: Rendering Realistic Room Impulse Response With Neural Fields
Susan Liang, Chao Huang, Yapeng Tian, Anurag Kumar, Chenliang Xu
ICCVW'23: ICCV AV4D Workshop .
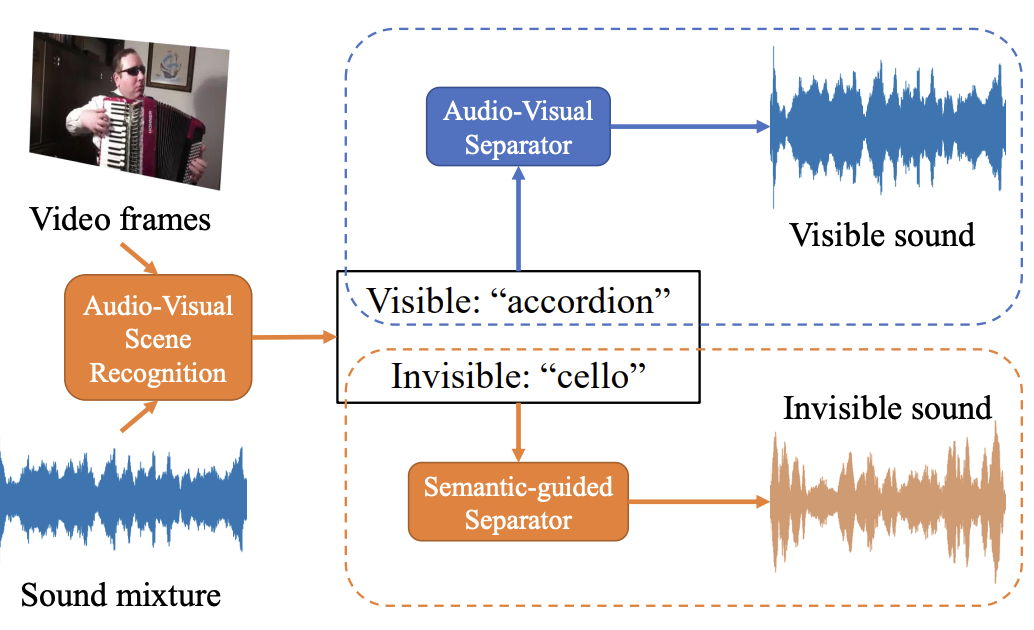
Separating Invisible Sounds Toward Universal Audio-Visual Scene-Aware Sound Separation
Yiyang Su, Ali Vosoughi, Shijian Deng, Yapeng Tian, Chenliang Xu
ICCVW'23: ICCV AV4D Workshop .
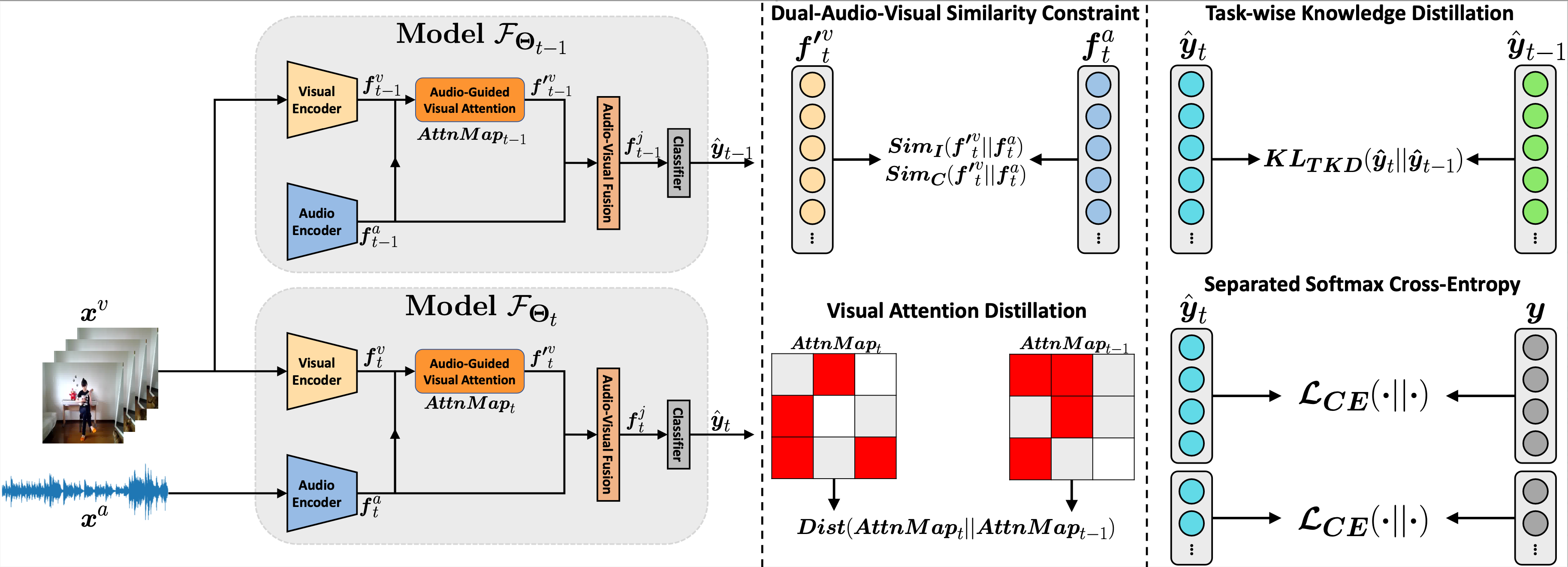
Audio-Visual Class-Incremental Learning
Weiguo Pian‡, Shentong Mo‡, Yunhui Guo, Yapeng Tian
ICCV'23: IEEE/CVF International Conference on Computer Vision.
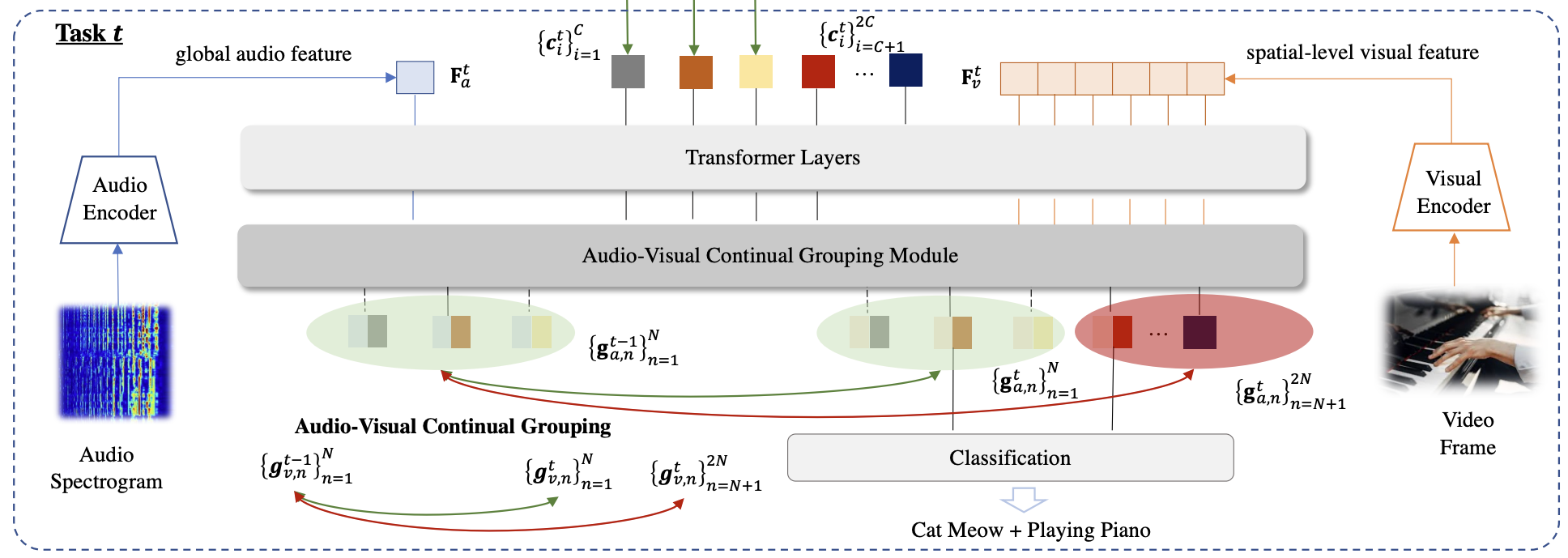
Class-Incremental Grouping Network for Continual Audio-Visual Learning
Shentong Mo‡, Weiguo Pian‡, Yapeng Tian
ICCV'23: IEEE/CVF International Conference on Computer Vision.
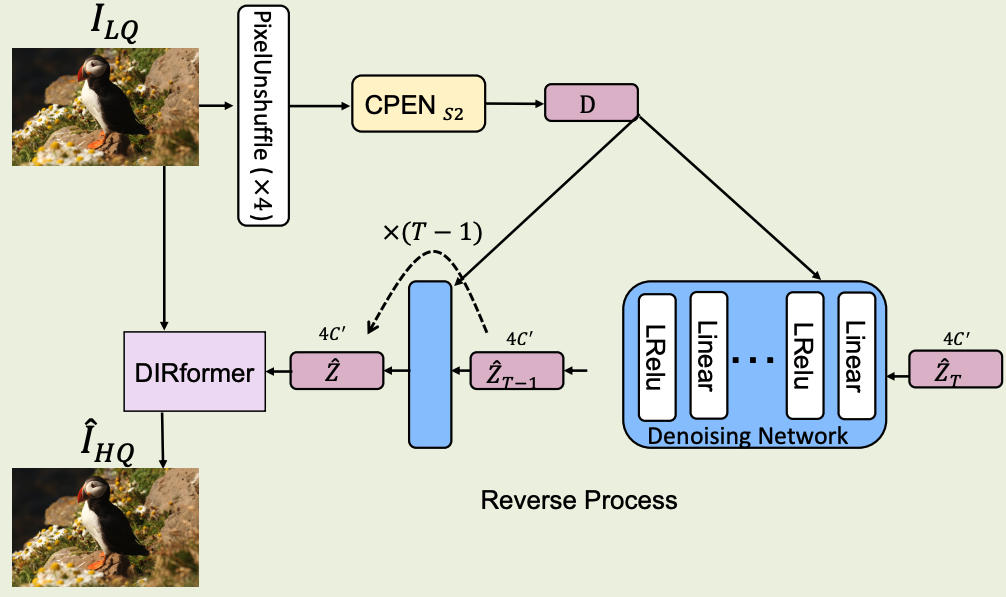
DiffIR: Efficient Diffusion Model for Image Restoration
Bin Xia, Yulun Zhang, Shiyin Wang, Yitong Wang, Xinglong Wu, Yapeng Tian, Wenming Yang, Luc Van Gool
ICCV'23: IEEE/CVF International Conference on Computer Vision.
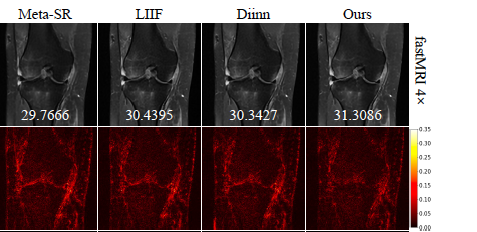
Dual Arbitrary Scale Super-Resolution for Multi-Contrast MRI
Jiamiao Zhang, Yichen Chi, Jun Lyu, Wenming Yang, Yapeng Tian
MICCAI'23: Medical Image Computing and Computer-Assisted Intervention.

Meta-Learning based Degradation Representation for Blind Super-Resolution
Bin Xia, Yapeng Tian, Yulun Zhang, Yucheng Hang, Wenming Yang, Qingmin Liao
TIP'23: IEEE Transactions on Image Processing.

AV-SAM: Segment Anything Model Meets Audio-Visual Localization and Segmentation
Shentong Mo, Yapeng Tian
CVPRW'23: CVPR Sight and Sound Workshop.
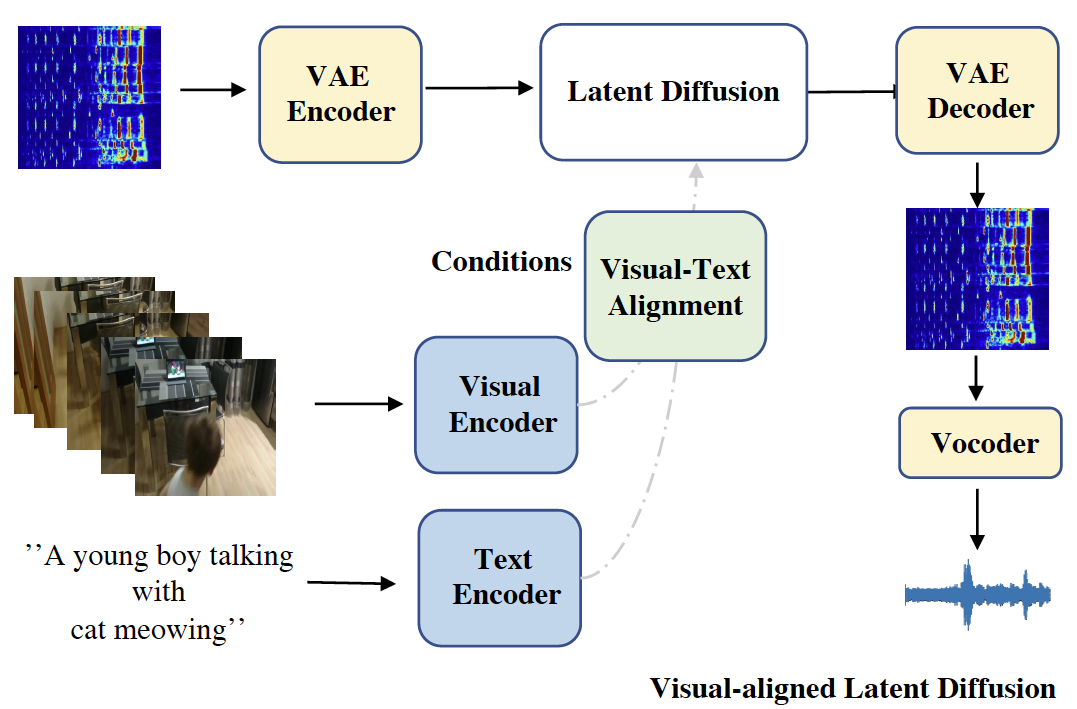
DiffAVA: Personalized Text-to-Audio Generation with Visual Alignment
Shentong Mo, Jing Shi, Yapeng Tian
CVPRW'23: CVPR Sight and Sound Workshop.
AV-NeRF: Learning Neural Fields for Real-World Audio-Visual Scene Synthesis
Susan Liang, Chao Huang, Yapeng Tian, Anurag Kumar, Chenliang Xu
CVPRW'23: CVPR Sight and Sound Workshop.
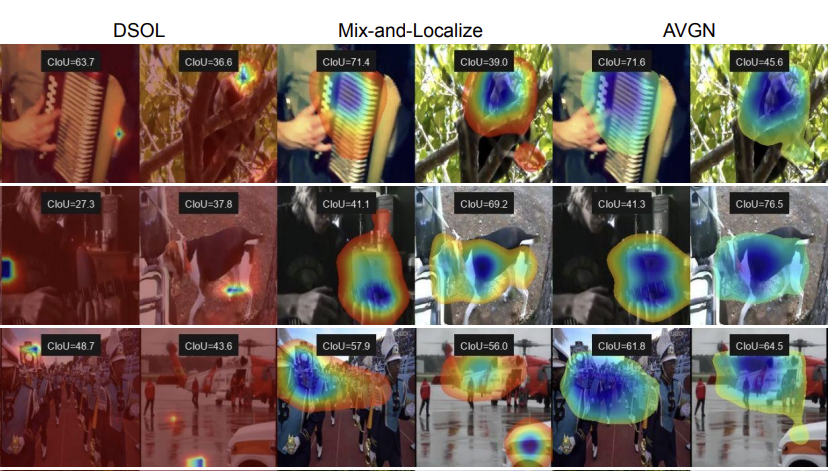
Audio-Visual Grouping Network for Sound Localization from Mixtures
Shentong Mo, Yapeng Tian
CVPR'23: IEEE/CVF Conference on Computer Vision and Pattern Recognition.
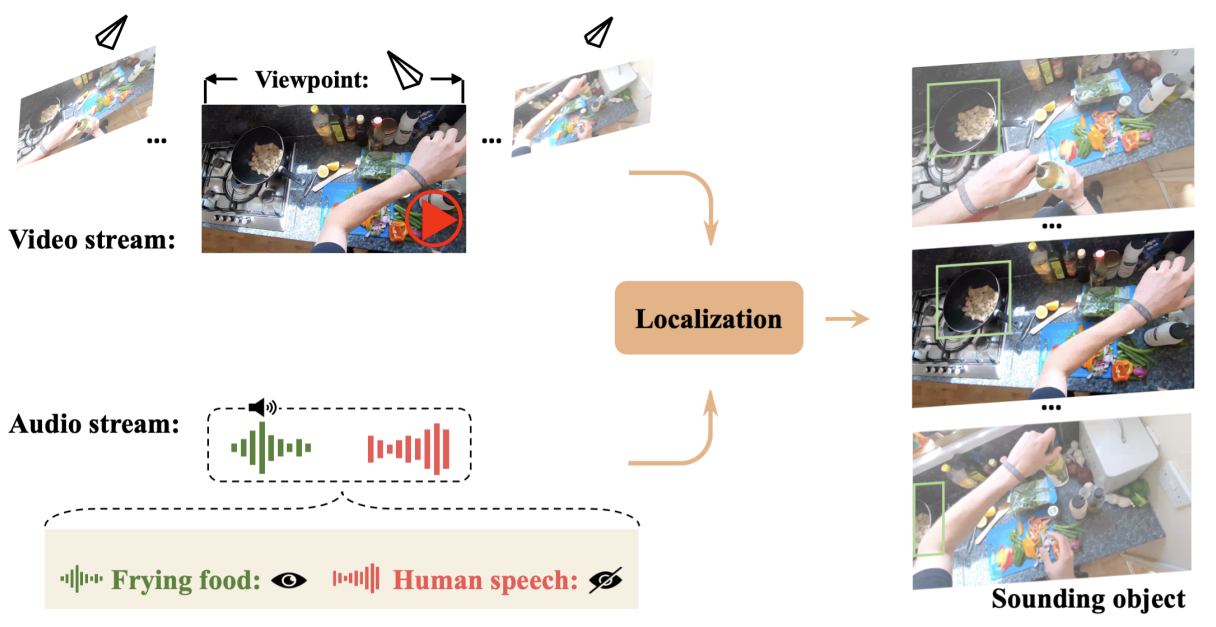
Egocentric Audio-Visual Object Localization
Chao Huang, Yapeng Tian, Anurag Kumar, and Chenliang Xu
CVPR'23: IEEE/CVF Conference on Computer Vision and Pattern Recognition.
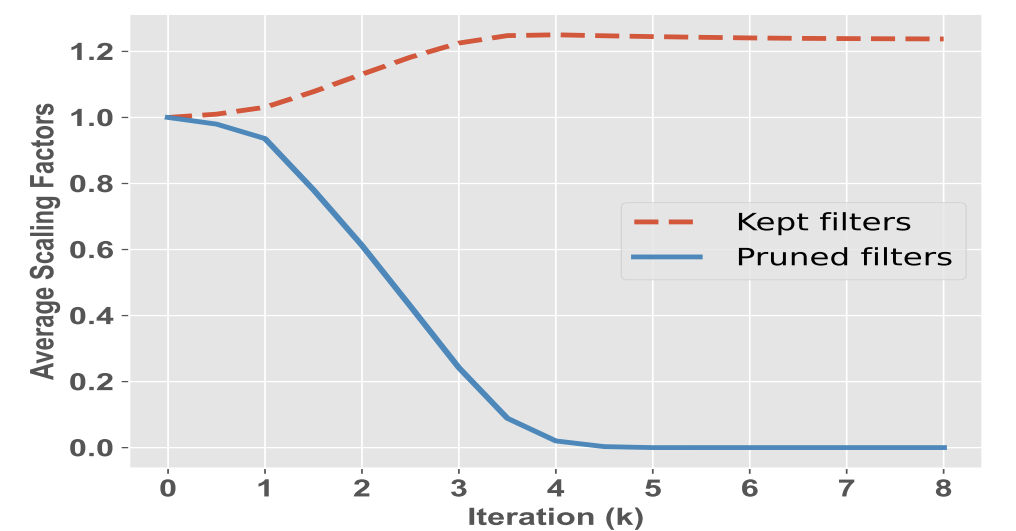
Structured Sparsity Learning for Efficient Video Super-Resolution
Bin Xia, Jingwen He, Yulun Zhang, Yitong Wang, Yapeng Tian, Wenming Yang, Luc Van Gool
CVPR'23: IEEE/CVF Conference on Computer Vision and Pattern Recognition.
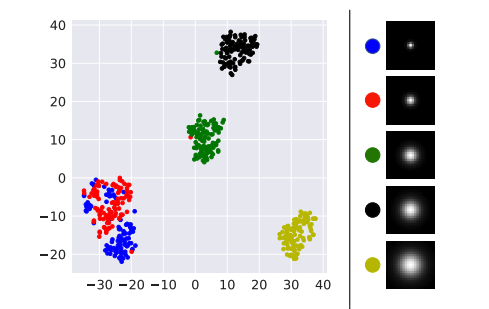
Knowledge Distillation based Degradation Estimation for Blind Super-Resolution
Bin Xia, Yulun Zhang, Yitong Wang, Yapeng Tian, Wenming Yang, Radu Timofte, Luc Van Gool
ICLR'23: International Conference on Learning Representations.
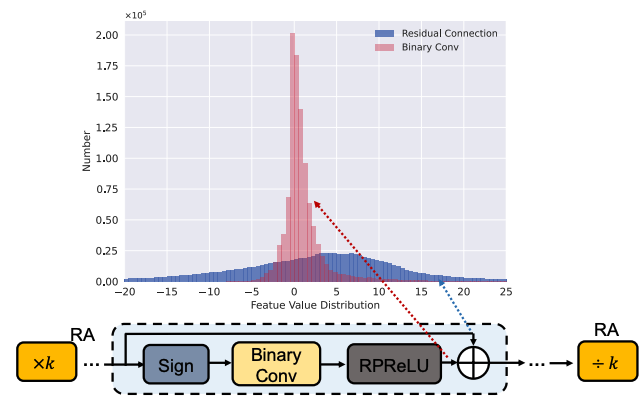
Basic Binary Convolution Unit for Binarized Image Restoration Network
Bin Xia, Yulun Zhang, Yitong Wang, Yapeng Tian, Wenming Yang, Radu Timofte, Luc Van Gool
ICLR'23: International Conference on Learning Representations.
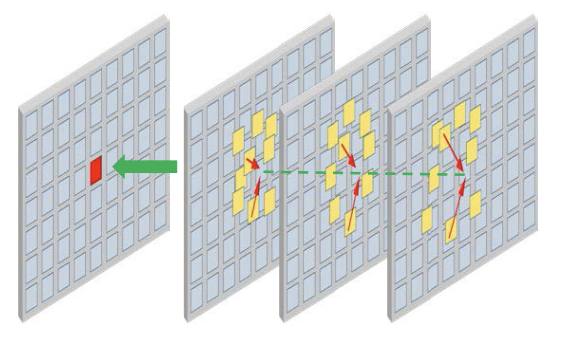
Stdan: deformable attention network for space-time video super-resolution
Hai Wang, Xiaoyu Xiang, Yapeng Tian, Wenming Yang, Qingmin Liao
TNNLS'23: IEEE Transactions on Neural Networks and Learning Systems.

GDSSR: Toward Real-World Ultra-High-Resolution Image Super-Resolution
Yichen Chi, Wenming Yang, Yapeng Tian
SPL'23: IEEE Signal Processing Letters.

Towards Unified, Explainable, and Robust Multisensory Perception
Yapeng Tian
AAAI'23: AAAI Conference on Artificial Intelligence. (NFH program)
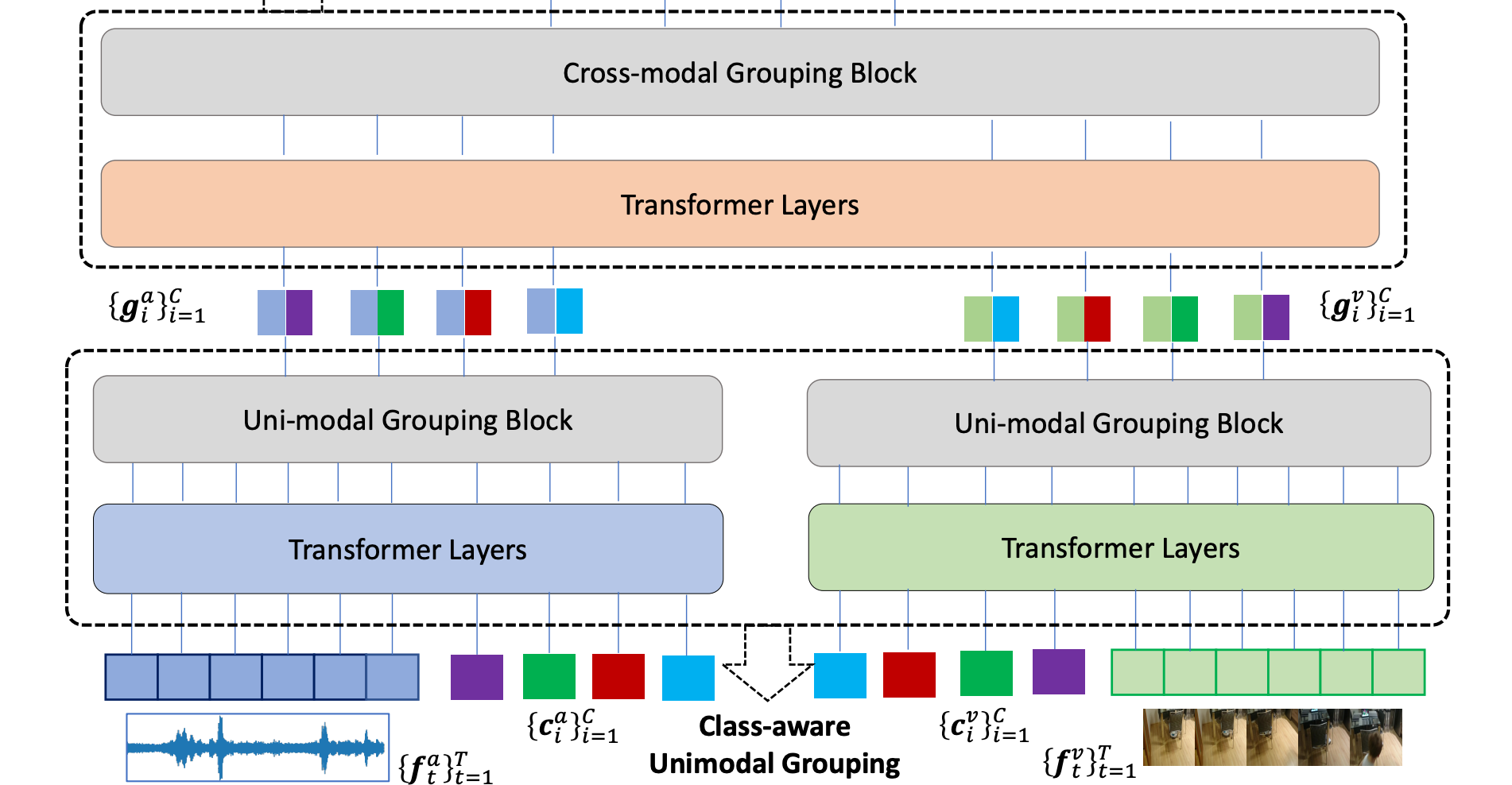
Multi-modal Grouping Network for Weakly-Supervised Audio-Visual Video Parsing
Shentong Mo, Yapeng Tian
NeurIPS'22: The Annual Conference on Neural Information Processing Systems.
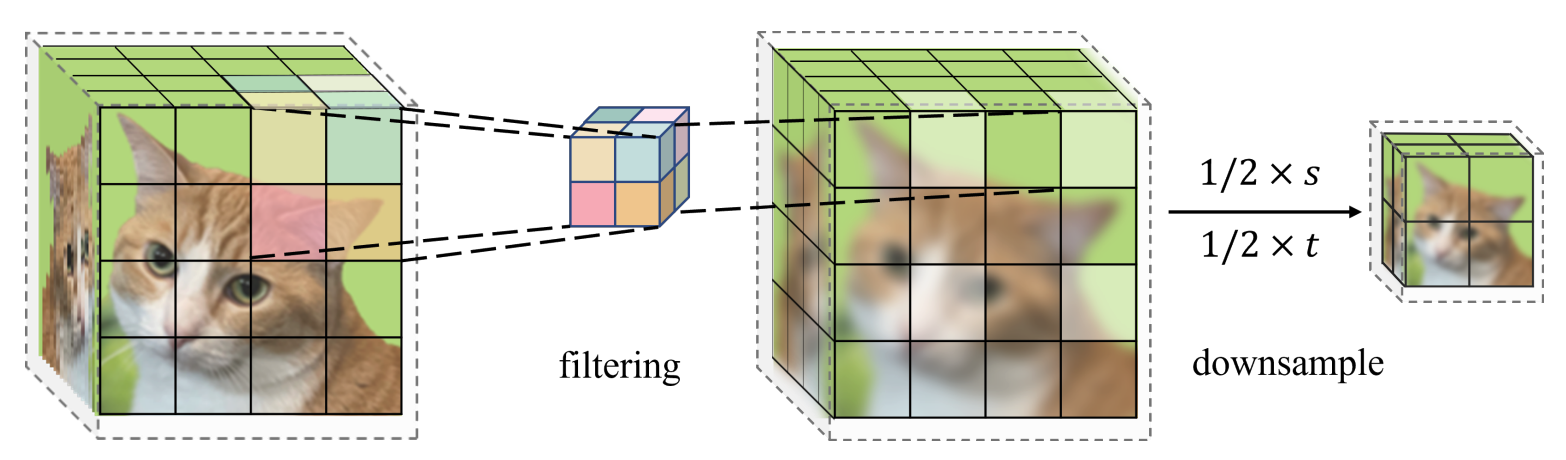
Learning Spatio-Temporal Downsampling for Effective Video Upscaling
Xiaoyu Xiang, Yapeng Tian, Vijay Rengarajan, Lucas Young, Bo Zhu, Rakesh Ranjan
ECCV'22: European Conference on Computer Vision.
Audio-Visual Scene Understanding Towards Unified, Explainable, and Robust Multisensory Perception
Yapeng Tian
PhD Thesis
DuDoCAF: Dual-Domain Cross-Attention Fusion with Recurrent Transformer for Fast Multi-contrast MR Imaging
Jun Lyu, Bin Sui, Chengyan Wang, Yapeng Tian, Qi Dou, and Jing Qin
MICCAI'22: Medical Image Computing and Computer Assisted Intervention.
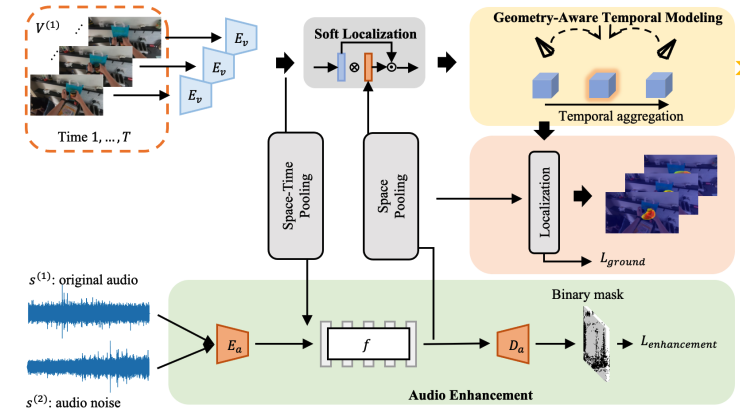
Audio-Visual Object Localization in Egocentric Videos
Chao Huang, Yapeng Tian, Anurag Kumar, and Chenliang Xu
CVPRW'22: CVPR Workshops
Egocentric audio-visual learning.
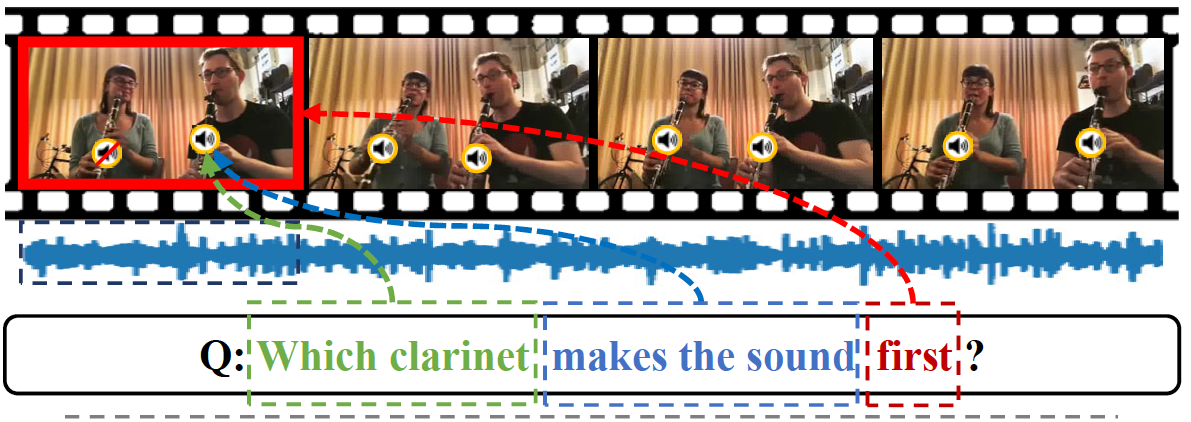
Learning to Answer Questions in Dynamic Audio-Visual Scenarios
Guangyao Li‡, Yake Wei‡, Yapeng Tian‡, Chenliang Xu, Ji-Rong Wen, and Di Hu
CVPR'22 Oral: IEEE/CVF Conference on Computer Vision and Pattern Recognition.
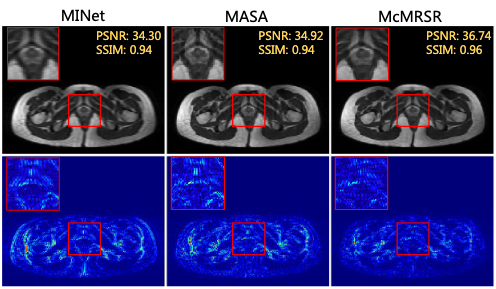
Transformer-empowered Multi-contrast MRI Super-Resolution
Guangyuan Li, Jun Lv, Yapeng Tian, Qi Dou, Chengyan Wang, Chenliang Xu, Jing Qin
CVPR'22: IEEE/CVF Conference on Computer Vision and Pattern Recognition.

Coarse-to-Fine Embedded PatchMatch and Multi-Scale Dynamic Aggregation for Reference-based Super-Resolution
Bin Xia, Yapeng Tian, Yucheng Hang, Wenming Yang, Qingmin Liao, Jie Zhou
AAAI'22: The AAAI Conference on Artificial Intelligence.

Efficient Non-Local Contrastive Attention for Image Super-Resolution
Bin Xia‡, Yucheng Hang‡, Yapeng Tian, Wenming Yang, Qingmin Liao, Jie Zhou
AAAI'22: The AAAI Conference on Artificial Intelligence.
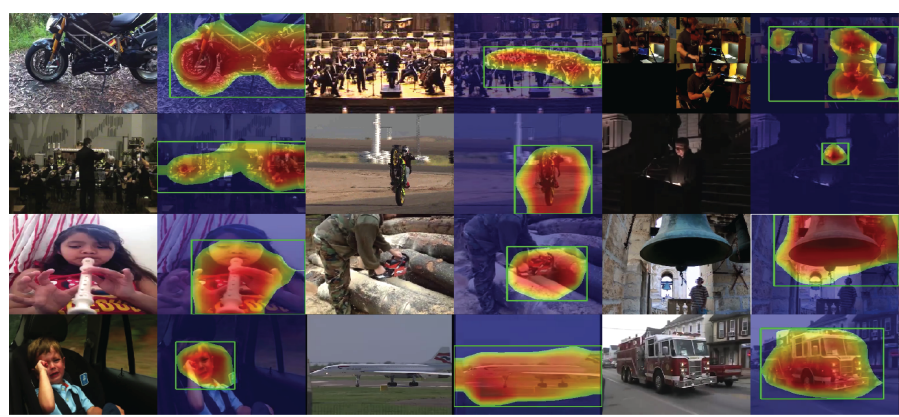
Space-Time Memory Network for Sounding Object Localization in Videos
Sizhe Li‡, Yapeng Tian‡, and Chenliang Xu
BMVC'21: The British Machine Vision Conference.

Video Matting via Consistency-Regularized Graph Neural Networks
Tiantian Wang, Sifei Liu, Yapeng Tian, Kai Li, and Ming-Hsuan Yang
ICCV'21: IEEE/CVF International Conference on Computer Vision.
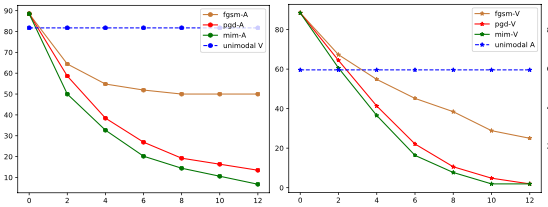
Can audio-visual integration strengthen robustness under multimodal attacks?
Yapeng Tian and Chenliang Xu
CVPR'21: IEEE/CVF Conference on Computer Vision and Pattern Recognition.
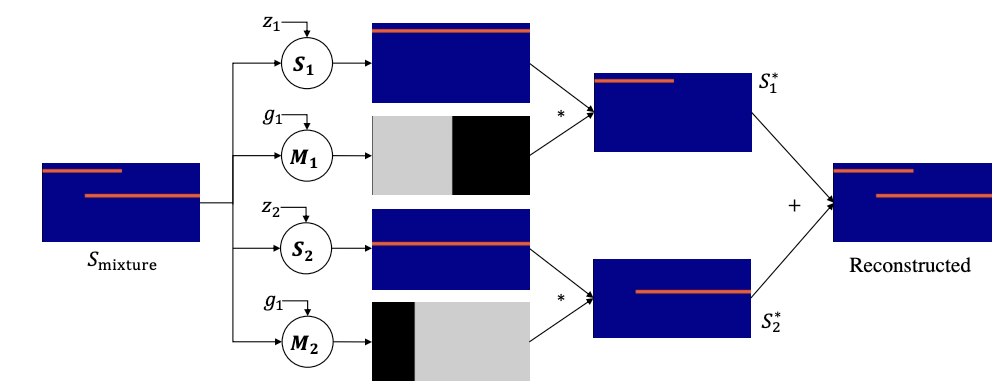
Cyclic Co-Learning of Sounding Object Visual Grounding and Sound Separation
Yapeng Tian, Di Hu, and Chenliang Xu
CVPR'21: IEEE/CVF Conference on Computer Vision and Pattern Recognition.
Unified Multisensory Perception: Weakly-Supervised Audio-Visual Video Parsing
Yapeng Tian, Dingzeyu Li, and Chenliang Xu
ECCV'20 Spotlight: European Conference on Computer Vision.

Zooming Slow-Mo: Fast and Accurate One-Stage Space-Time Video Super-Resolution
Xiaoyu Xiang‡, Yapeng Tian‡, Yulun Zhang, Yun Fu, Jan Allebach, and Chenliang Xu
CVPR'20: IEEE/CVF Conference on Computer Vision and Pattern Recognition.

TDAN: Temporally Deformable Alignment Network for Video Super-Resolution
Yapeng Tian, Yulun Zhang, Yun Fu, and Chenliang Xu
CVPR'20: IEEE/CVF Conference on Computer Vision and Pattern Recognition.
This is the first work that uses deformable alignment to address video restoration.
Deep Audio Prior
Yapeng Tian, Chenliang Xu, and Dingzeyu Li
CVPRW'20: CVPR Workshops.
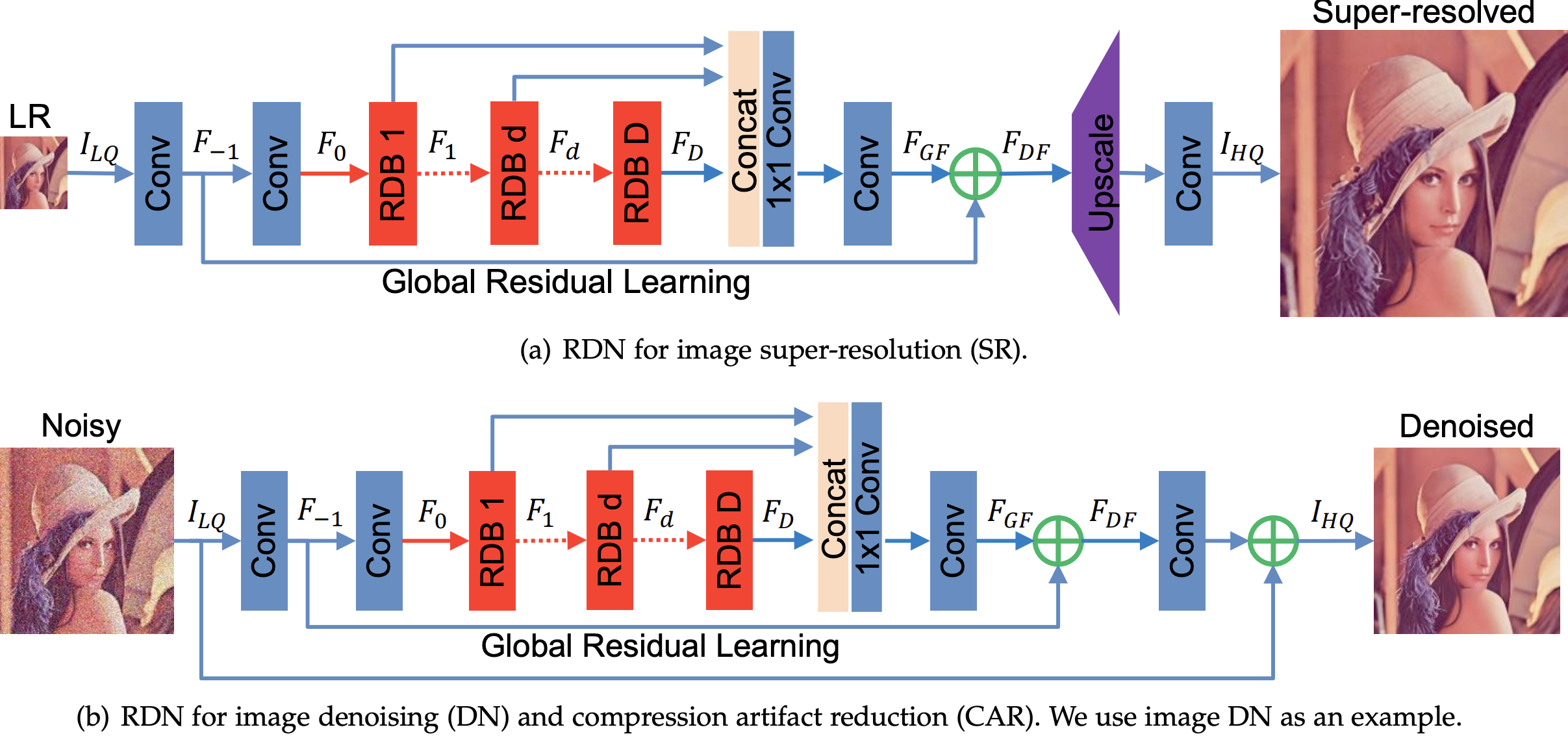
Residual Dense Network for Image Super-Resolution
Yulun Zhang, Yapeng Tian, Yu Kong , Bineng Zhong, Yun Fu
TPAMI'20: IEEE Transactions on Pattern Analysis and Machine Intelligence.

CFSNet: Toward a Controllable Feature Space for Image Restoration
Wei Wang‡, Ruiming Guo‡, Yapeng Tian, and Wenming Yang
ICCV'19: IEEE/CVF International Conference on Computer Vision.

Interpretable and Controllable Audio-Visual Video Captioning
Yapeng Tian, Chenxiao Guan, Goodman Justin, Marc Moore, and Chenliang Xu
CVPRW'19: CVPR Workshops.
Multisensory interpretability in terms of the audio-visual video captioning task.
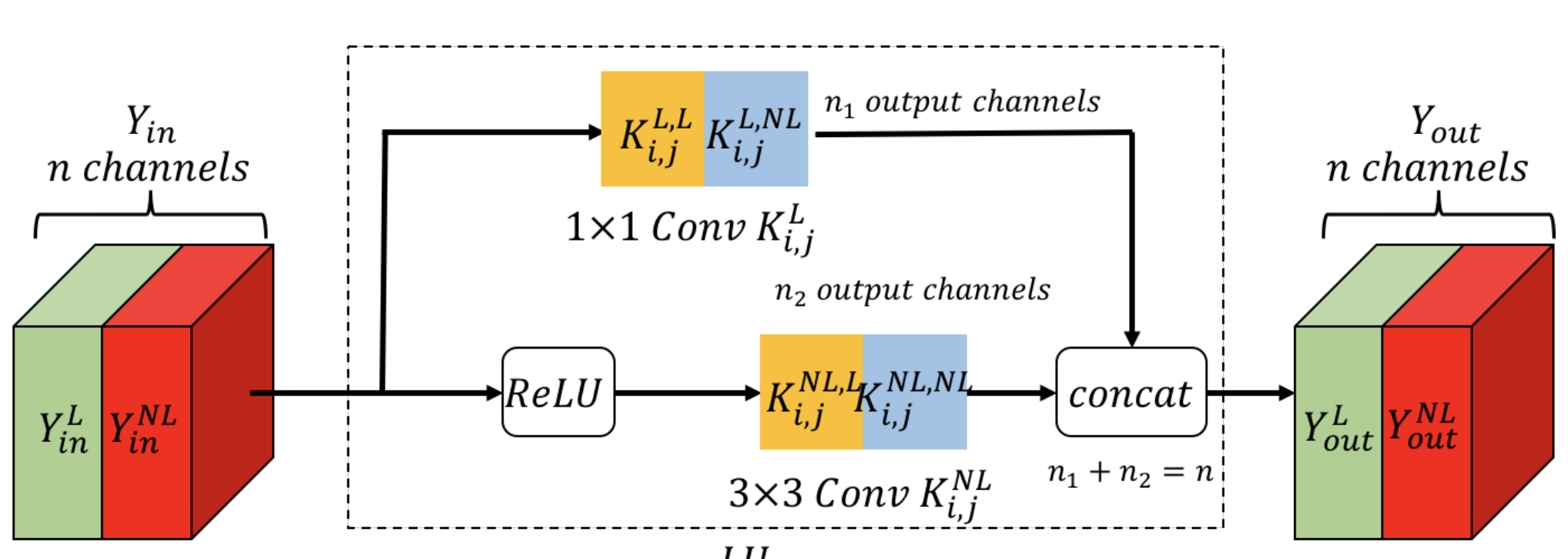
LCSCNet: Linear Compressing Based Skip-Connecting Network for ISR
Wenming Yang, Xuechen Zhang, Yapeng Tian, Wei Wang, Jing-Hao Xue, Qingmin Liao
TIP'19: IEEE Trans. Image Processing.

Deep Learning for Single Image Super-Resolution: A Brief Review
Wenming Yang, Xuechen Zhang, Yapeng Tian, Wei Wang, JingHao Xue, Qingmin Liao
TMM'19: IEEE Trans. Multimedia.

Audio-Visual Event Localization in Unconstrained Videos
Yapeng Tian, Jing Shi, Bochen Li, Zhiyao Duan, Chenliang Xu
ECCV'18: European Conference on Computer Vision.
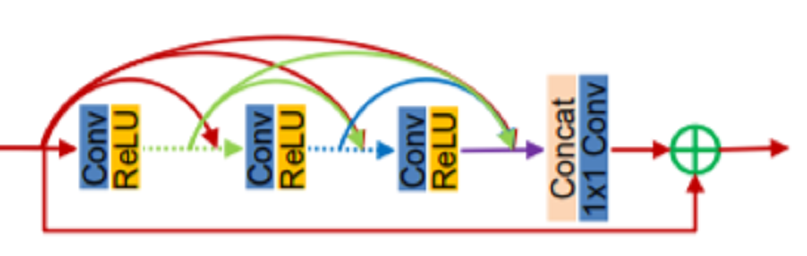
Residual Dense Network for Image Super-Resolution
Yulun Zhang, Yapeng Tian, Yu Kong , Bineng Zhong, Yun Fu
CVPR'18 Spotlight: IEEE/CVF Conf. on Computer Vision and Pattern Recognition.
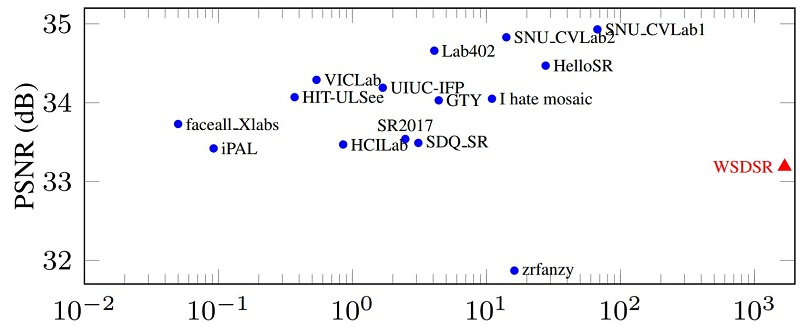
NTIRE 2017 Challenge on Single Image Super-Resolution: Methods and Results
Timofte et al.
CVPRW'17: CVPR Workshops.
Consistent Coding Scheme for Single-Image Super-Resolution
Wenming Yang, Yapeng Tian, Fei Zhou, Qingmin Liao, Hai Chen, Chenglin Zheng
TMM'16: EEE Trans. Multimedia. (First student author)
Anchored Neighborhood Regression based SISR from Self-examples
Yapeng Tian, Fei Zhou, Wenming Yang, Xuesen Shang, Qingmin Liao
ICIP'16: IEEE International Conference on Image Processing.
SISR Using Clustering-Based Global Regression and Propagation Filtering
Wenming Yang, Yapeng Tian, Fei Zhou, ..., Qingmin Liao
ACPR'15 Oral: Asian Conference on Pattern Recognition. (First student author)
Learning in Audio-visual Context: A Review, Analysis, and New Perspective
Yake Wei, Di Hu, Yapeng Tian, Xuelong Li
Preprint'22.
Learning in Audio-visual Context: A Review, Analysis, and New Perspective
Yake Wei, Di Hu, Yapeng Tian, Xuelong Li
Preprint'22.
Modality-Inconsistent Continual Learning of Multimodal Large Language Models
Weiguo Pian, Shijian Deng, Shentong Mo, Mingrui Liu, Yunhui Guo, Yapeng Tian
TMLR'26: Transactions on Machine Learning Research.
OmniSonic: Towards Universal and Holistic Audio Generation from Video and Text
Weiguo Pian, Saksham Singh Kushwaha, Zhimin Chen, Shijian Deng, Kai Wang, Yunhui Guo, Yapeng Tian
CVPR'26: IEEE/CVF Conference on Computer Vision and Pattern Recognition.
Omni-MMSI: Toward Identity-attributed Social Interaction Understanding
Xinpeng Li, Bolin Lai, Hardy Chen, Shijian Deng, Cihang Xie, Yuyin Zhou, James Matthew Rehg, Yapeng Tian
CVPR'26: IEEE/CVF Conference on Computer Vision and Pattern Recognition.
Hear What You See: Video-to-Audio Generation with Diffusion Transformer and Semantic-Temporal Alignment-Ranked Direct Preference Optimization
Kai Wang, Tao Zhou, jiayi lei, Jing Wang, Jinman Zhao, Weiguo Pian, Yuan Cheng, Yapeng Tian, Peng Gao, Bin Fu, Yihao Liu, Dimitrios Hatzinakos, Yuewen Cao
CVPR'26: IEEE/CVF Conference on Computer Vision and Pattern Recognition.
Towards Online Multi-Modal Social Interaction Understanding
Xinpeng Li, Shijian Deng, Bolin Lai, Weiguo Pian, James M. Rehg, Yapeng Tian
TMLR'26: Transactions on Machine Learning Research.
Do Audio-Visual Segmentation Models Truly Segment Sounding Objects?
Jia Li, Wenjie Zhao, Ziru Huang, Yunhui Guo, Yapeng Tian
AAAI'26: Annual AAAI Conference on Artificial Intelligence.
Touch with Meaning: A Contextual Analysis of Social Touch
Ayush Bhardwaj, Ashish Pratap, Abbas Khawaja, Yapeng Tian, Uison Ju, Dajin Lee, Seungmoon Choi, and Jin Ryong Kim
CHI'26: ACM CHI Conference on Human Factors in Computing Systems.
AVROBUSTBENCH: Benchmarking the Robustness of Audio-Visual Recognition Models at Test-Time
Sarthak Kumar Maharana, Saksham Singh Kushwaha, Baoming Zhang, Adrian Rodriguez, Songtao Wei, Yapeng Tian, Yunhui Guo
NeurIPS'25: Conference on Neural Information Processing Systems (D&B Track).
AV-DiT: Efficient Audio-Visual Diffusion Transformer for Joint Audio and Video Generation
Kai Wang, Shijian Deng, Jing Shi, Dimitrios Hatzinakos, Yapeng Tian
ACM MM'25: ACM International Conference on Multimedia.
High-Quality Sound Separation Across Diverse Categories via Visually-Guided Generative Modeling
Chao Huang, Susan Liang, Yapeng Tian, Anurag Kumar, Chenliang Xu
IJCV'25: International Journal of Computer Vision.
Prompt Image to Watch and Hear: Multimodal Prompting for Parameter-Efficient Audio-Visual Learning
Kai Wang, Shentong Mo, Yapeng Tian, Dimitrios Hatzinakos
BMVC'25: The British Machine Vision Conference (BMVC).
VinTAGe: Joint Video and Text Conditioning for Holistic Audio Generation
Saksham Singh Kushwaha, Yapeng Tian
CVPR'25: IEEE/CVF Conference on Computer Vision and Pattern Recognition.
Diff-SAGe: End-to-End Spatial Audio Generation Using Diffusion Models
Saksham Singh Kushwaha, Jianbo Ma, Mark R. P. Thomas, Yapeng Tian, and Avery Bruni
ICASSP'25: IEEE International Conference on Acoustics, Speech, and Signal Processing.
MagicTalk: Implicit and Explicit Correlation Learning for Diffusion-based Emotional Talking Face Generation
Chenxu Zhang, Chao Wang, Jianfeng Zhang, Hongyi Xu, Guoxian Song, You Xie, Linjie Luo, Yapeng Tian, Jiashi Feng, Xiaohu Guo
CVM: Computational Visual Media Journal.
Joint Co-Speech Gesture and Expressive Talking Face Generation using Diffusion with Adapters
Steven Hogue, Chenxu Zhang, Yapeng Tian, Xiaohu Guo
WACV'25: IEEE/CVF Winter Conference on Applications of Computer Vision.
Audio-Visual Dataset Distillation
Saksham Singh Kushwaha, Siva Sai Nagender Vasireddy, Kai Wang, Yapeng Tian
TMLR'24: Transactions on Machine Learning Research
Continual Audio-Visual Sound Separation
Weiguo Pian, Yiyang Nan, Shijian Deng, Shentong Mo, Yunhui Guo, Yapeng Tian
NeurIPS'24: The Annual Conference on Neural Information Processing Systems
Hear Me, See Me, Understand Me: Audio-Visual Autism Behavior Recognition
Shijian Deng, Erin Kosloski, Siddhi Patel, Zeke A Barnett, Yiyang Nan, Alexander M Kaplan, Sisira Aarukapalli, William Doan, Matthew Wang, Harsh Singh, Rollins Pamela, Yapeng Tian
TMM'24: IEEE Transactions on Multimedia.
emoji_events DAVIS: High-Quality Audio-Visual Separation with Generative Diffusion Models
(Best Paper Honorable Mention)
Chao Huang, Susan Liang, Yapeng Tian, Anurag Kumar, Chenliang Xu
ACCV'24 Oral: Asian Conference on Computer Vision.
Language-Guided Joint Audio-Visual Editing Via One-Shot Adaptation
Susan Liang, Chao Huang, Yapeng Tian, Anurag Kumar, Chenliang Xu
ACCV'24: Asian Conference on Computer Vision.
SaSR-Net: Source-Aware Semantic Representation Network for Enhancing Audio-Visual Question Answering
Tianyu Yang, Yiyang Nan, Lisen Dai, Zhenwen Liang, Yapeng Tian, Xiangliang Zhang
EMNLP'24: Empirical Methods in Natural Language Processing (Findings)
Towards Long Form Audio-visual Video Understanding
Wenxuan Hou, Guangyao Li, Yapeng Tian, Di Hu
TOMM'24: ACM Trans. on Multimedia Computing, Communications and App.
MIMOSA: Human-AI Co-Creation of Computational Spatial Audio Effects on Videos
Zheng Ning, Zheng Zhang, Jerrick Ban, Kaiwen Jiang, Ruohong Gan, Yapeng Tian, Toby Jia-Jun Li
C&C'24: ACM Conference on Creativity & Cognition.
AV-Mamba: Cross-Modality Selective State Space Models for Audio-Visual Question Answering
Ziru Huang, Jia Li, Wenjie Zhao, Yunhui Guo, Yapeng Tian
CVPRW'24: CVPR Signt and Sound Workshop
Learning Continual Audio-Visual Sound Separation Models
Weiguo Pian, Yiyang Nan, Shijian Deng, Shentong Mo, Yunhui Guo, Yapeng Tian
CVPRW'24: CVPR Signt and Sound Workshop
Audio-Visual Autism Behavior Recognition with MMLMs
Shijian Deng, Erin Kosloski, Siddhi Patel, Zeke A Barnett, Yiyang Nan, Alexander M Kaplan, Sisira Aarukapalli, William Doan, Matthew Wang, Harsh Singh, Rollins Pamela, Yapeng Tian
CVPRW'24: CVPR Signt and Sound Workshop
Dataset distillation for audio-visual datasets
Saksham Singh Kushwaha, Siva Sai Nagender Vasireddy, Kai Wang, Yapeng Tian
CVPRW'24: CVPR Signt and Sound Workshop
DiffTED: One-shot Audio-driven TED Talk Video Generation with Diffusion-based Co-speech Gestures
Steven Hogue, Chenxu Zhang, Hamza Daruger, Yapeng Tian, Xiaohu Guo
CVPRW'24: CVPR HuMoGen Workshop
Towards Efficient Audio-Visual Learners via Empowering Pre-trained Vision Transformers with Cross-Modal Adaptation
Kai Wang, Yapeng Tian, Dimitrios Hatzinakos
CVPRW'24: CVPR Multimodal Foundation Models Workshop
MA-AVT: Modality Alignment for Parameter-Efficient Audio-Visual Transformers
Tanvir Mahmud, Shentong Mo, Yapeng Tian, Diana Marculescu
CVPRW'24: CVPR Efficient Deep Learning for Computer Vision Workshop
T-VSL: Text-Guided Visual Sound Source Localization in Mixtures
Tanvir Mahmud, Yapeng Tian, Diana Marculescu
CVPR'24: IEEE/CVF Conference on Computer Vision and Pattern Recognition
SPICA: Interactive Video Content Exploration through Augmented Audio Descriptions for Blind or Low-Vision Viewers
Zheng Ning, Brianna Wimer, Kaiwen Jiang, Keyi Chen, Jerrick Ban, Yapeng Tian, Yuhang Zhao, Toby Li
CHI'24: The ACM Conference on Human Factors in Computing Systems.
LAVSS: Location-Guided Audio-Visual Spatial Audio Separation
Yuxin Ye, Wenming Yang, Yapeng Tian
WACV'24: Winter Conference on Applications of Computer Vision.
Disentangled counterfactual learning for physical audiovisual commonsense reasoning
Changsheng Lv, Shuai Zhang, Yapeng Tian, Mengshi Qi, Huadong Ma
NeurIPS'23: The Annual Conference on Neural Information Processing Systems.
AV-NeRF: Learning Neural Fields for Real-World Audio-Visual Scene Synthesis
Susan Liang, Chao Huang, Yapeng Tian, Anurag Kumar, Chenliang Xu
NeurIPS'23: The Annual Conference on Neural Information Processing Systems.
PEANUT: A Human-AI Collaborative Tool for Annotating Audio-Visual Data
Zheng Zhang‡, Zheng Ning‡, Chenliang Xu Yapeng Tian, Toby Jia-Jun Li
UIST'23: ACM Symposium on User Interface Software and Technology.
Towards Robust Active Speaker Detection
Siva Sai Nagender Vasireddy, Chenxu Zhang, Xiaohu Guo, Yapeng Tian
ICCVW'23: ICCV AV4D Workshop .
Position-Aware Audio-Visual Separation for Spatial Audio
Yuxin Ye, Wenming Yang, Yapeng Tian
ICCVW'23: ICCV AV4D Workshop .
Towards Better Egocentric Action Understanding in a Multi-Input Multi-Output View
Wenxuan Hou, Ruoxuan Feng, Yixin Xu, Yapeng Tian, Di Hu
ICCVW'23: ICCV AV4D Workshop .
Neural Acoustic Context Field: Rendering Realistic Room Impulse Response With Neural Fields
Susan Liang, Chao Huang, Yapeng Tian, Anurag Kumar, Chenliang Xu
ICCVW'23: ICCV AV4D Workshop .
Separating Invisible Sounds Toward Universal Audio-Visual Scene-Aware Sound Separation
Yiyang Su, Ali Vosoughi, Shijian Deng, Yapeng Tian, Chenliang Xu
ICCVW'23: ICCV AV4D Workshop .
Audio-Visual Class-Incremental Learning
Weiguo Pian‡, Shentong Mo‡, Yunhui Guo, Yapeng Tian
ICCV'23: IEEE/CVF International Conference on Computer Vision.
Class-Incremental Grouping Network for Continual Audio-Visual Learning
Shentong Mo‡, Weiguo Pian‡, Yapeng Tian
ICCV'23: IEEE/CVF International Conference on Computer Vision.
AV-SAM: Segment Anything Model Meets Audio-Visual Localization and Segmentation
Shentong Mo, Yapeng Tian
CVPRW'23: CVPR Sight and Sound Workshop.
DiffAVA: Personalized Text-to-Audio Generation with Visual Alignment
Shentong Mo, Jing Shi, Yapeng Tian
CVPRW'23: CVPR Sight and Sound Workshop.
AV-NeRF: Learning Neural Fields for Real-World Audio-Visual Scene Synthesis
Susan Liang, Chao Huang, Yapeng Tian, Anurag Kumar, Chenliang Xu
CVPRW'23: CVPR Sight and Sound Workshop.
Audio-Visual Grouping Network for Sound Localization from Mixtures
Shentong Mo, Yapeng Tian
CVPR'23: IEEE/CVF Conference on Computer Vision and Pattern Recognition.
Egocentric Audio-Visual Object Localization
Chao Huang, Yapeng Tian, Anurag Kumar, and Chenliang Xu
CVPR'23: IEEE/CVF Conference on Computer Vision and Pattern Recognition.
Towards Unified, Explainable, and Robust Multisensory Perception
Yapeng Tian
AAAI'23: AAAI Conference on Artificial Intelligence. (NFH program)
Multi-modal Grouping Network for Weakly-Supervised Audio-Visual Video Parsing
Shentong Mo, Yapeng Tian
NeurIPS'22: The Annual Conference on Neural Information Processing Systems.
Audio-Visual Scene Understanding Towards Unified, Explainable, and Robust Multisensory Perception
Yapeng Tian
PhD Thesis
Audio-Visual Object Localization in Egocentric Videos
Chao Huang, Yapeng Tian, Anurag Kumar, and Chenliang Xu
CVPRW'22: CVPR Workshops
Egocentric audio-visual learning.
Learning to Answer Questions in Dynamic Audio-Visual Scenarios
Guangyao Li‡, Yake Wei‡, Yapeng Tian‡, Chenliang Xu, Ji-Rong Wen, and Di Hu
CVPR'22 Oral: IEEE/CVF Conference on Computer Vision and Pattern Recognition.
Space-Time Memory Network for Sounding Object Localization in Videos
Sizhe Li‡, Yapeng Tian‡, and Chenliang Xu
BMVC'21: The British Machine Vision Conference.
Can audio-visual integration strengthen robustness under multimodal attacks?
Yapeng Tian and Chenliang Xu
CVPR'21: IEEE/CVF Conference on Computer Vision and Pattern Recognition.
Cyclic Co-Learning of Sounding Object Visual Grounding and Sound Separation
Yapeng Tian, Di Hu, and Chenliang Xu
CVPR'21: IEEE/CVF Conference on Computer Vision and Pattern Recognition.
Unified Multisensory Perception: Weakly-Supervised Audio-Visual Video Parsing
Yapeng Tian, Dingzeyu Li, and Chenliang Xu
ECCV'20 Spotlight: European Conference on Computer Vision.
Deep Audio Prior
Yapeng Tian, Chenliang Xu, and Dingzeyu Li
CVPRW'20: CVPR Workshops.
Interpretable and Controllable Audio-Visual Video Captioning
Yapeng Tian, Chenxiao Guan, Goodman Justin, Marc Moore, and Chenliang Xu
CVPRW'19: CVPR Workshops.
Multisensory interpretability in terms of the audio-visual video captioning task.
Audio-Visual Event Localization in Unconstrained Videos
Yapeng Tian, Jing Shi, Bochen Li, Zhiyao Duan, Chenliang Xu
ECCV'18: European Conference on Computer Vision.
Toward Gaze Target Detection of Young Autistic Children
Shijian Deng, Erin E. Kosloski, Siva Sai Nagender Vasireddy, Jia Li, Randi Sierra Sherwood, Feroz Mohamed Hatha, Siddhi Patel, Pamela R Rollins, Yapeng Tian
AAAI'26 Oral: AAAI Conference on Artificial Intelligence (Social Impact Track).
VRSight: An AI-Driven Scene Description System to Improve Virtual Reality Accessibility for Blind People
Daniel Killough, Justin Feng, Zheng Xue Ching, Daniel Wang, Rithvik Dyava, Yapeng Tian, Yuhang Zhao
UIST'25: ACM Symposium on User Interface Software and Technology.
AROMA: Mixed-Initiative AI Assistance for Non-Visual Cooking by Grounding Multi-modal Information Between Reality and Videos
Zheng Ning, Leyang Li, Daniel Killough, JooYoung Seo, Patrick Carrington, Yapeng Tian, Yuhang Zhao, Franklin Mingzhe Li, Toby Jia-Jun Li
UIST'25: ACM Symposium on User Interface Software and Technology.
Signllm: Sign language production large language models
Sen Fang, Chen Chen, Lei Wang, Ce Zheng, Chunyu Sui, Yapeng Tian
ICCVW'25: IEEE/CVF International Conference on Computer Vision CV4A11y Workshop.
Introduction to the First Workshop on Vision Foundation Models and Generative AI for Accessibility
Yapeng Tian, Yuhang Zhao, Jon E. Froehlich, Chu Li, Yuheng Wu
ICCVW'25: IEEE/CVF International Conference on Computer Vision CV4A11y Workshop.
Demonstration of VRSight: AI-Driven Real-Time Descriptions to Enhance VR Accessibility for Blind People
Daniel Killough, Justin Feng, Rithvik Dyava, Zheng Xue Ching, Daniel Wang, Yapeng Tian, Yuhang Zhao
CHI EA'25: Extended Abstracts of the CHI Conference
Leveraging AI to Assess Social Attention in Young Autistic Children
Erin Kosloski, Shijian Deng, Siva S. N. Vasireddy, Randi S. Sherwood, Feroz M. Hatha, Jia Li, Siddhi Patel, Yapeng Tian, Pamela Rollins
SRCLD'25: Symposium on Research in Child Language Disorders.
SignDiff: Learning Diffusion Models for American Sign Language Production
Sen Fang, Chunyu Sui, Yanghao Zhou, Xuedong Zhang, Hongbin Zhong, Yapeng Tian, Chen Chen
FGW'25: International Conference on Automatic Face and Gesture Recognition Workshop.
Hear Me, See Me, Understand Me: Audio-Visual Autism Behavior Recognition
Shijian Deng, Erin Kosloski, Siddhi Patel, Zeke A Barnett, Yiyang Nan, Alexander M Kaplan, Sisira Aarukapalli, William Doan, Matthew Wang, Harsh Singh, Rollins Pamela, Yapeng Tian
TMM'24: IEEE Transactions on Multimedia.
emoji_eventsTowards AI-Powered AR for Enhancing Sports Playability for People with Low Vision: An Exploration of ARSports (Best Paper Award)
Jaewook Lee, Yang Li, Dylan Bunarto, Eujean Lee, Olivia Wang, Adrian Rodriguez, Yuhang Zhao, Yapeng Tian, Jon E. Froehlich
ISMAR IDEATExR'24 : International Symposium on Mixed and Augmented Reality Workshop.
emoji_events CookAR: Affordance Augmentations in Wearable AR to Support Kitchen Tool Interactions for People with Low Vision (Belonging & Inclusion Best Paper Award)
Jaewook Lee, Andrew D. Tjahjadi, Jiho Kim, Junpu Yu, Minji Park, Jiawen Zhang, Jon E. Froehlich, Yapeng Tian, Yuhang Zhao
UIST'24: ACM Symposium on User Interface Software and Technology.
SPICA: Interactive Video Content Exploration through Augmented Audio Descriptions for Blind or Low-Vision Viewers
Zheng Ning, Brianna Wimer, Kaiwen Jiang, Keyi Chen, Jerrick Ban, Yapeng Tian, Yuhang Zhao, Toby Li
CHI'24: The ACM Conference on Human Factors in Computing Systems.
EgoVSR: Towards High-Quality Egocentric Video Super-Resolution
Yichen Chi, Junhao Gu, Jiamiao Zhang, Wenming Yang, Yapeng Tian
TCSVT'24: IEEE Transactions on Circuits and Systems for Video Technology.
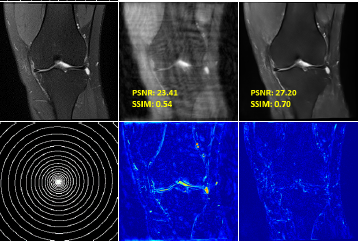
STADNet: Spatial-Temporal Attention-Guided Dual-Path Network for cardiac cine MRI super-resolution
Jun Lyu, Shuo Wang, Yapeng Tian, Jing Zou, Shunjie Dong, Chengyan Wang, Angelica I Aviles-Rivero, Jing Qin
MIA'24: Medical Image Analysis
Structured Sparsity Learning for Efficient Video Super-Resolution
Bin Xia, Jingwen He, Yulun Zhang, Yitong Wang, Yapeng Tian, Wenming Yang, Luc Van Gool
CVPR'23: IEEE/CVF Conference on Computer Vision and Pattern Recognition.
Stdan: deformable attention network for space-time video super-resolution
Hai Wang, Xiaoyu Xiang, Yapeng Tian, Wenming Yang, Qingmin Liao
TNNLS'23: IEEE Transactions on Neural Networks and Learning Systems.
Learning Spatio-Temporal Downsampling for Effective Video Upscaling
Xiaoyu Xiang, Yapeng Tian, Vijay Rengarajan, Lucas Young, Bo Zhu, Rakesh Ranjan
ECCV'22: European Conference on Computer Vision.
Video Matting via Consistency-Regularized Graph Neural Networks
Tiantian Wang, Sifei Liu, Yapeng Tian, Kai Li, and Ming-Hsuan Yang
ICCV'21: IEEE/CVF International Conference on Computer Vision.
Zooming Slow-Mo: Fast and Accurate One-Stage Space-Time Video Super-Resolution
Xiaoyu Xiang‡, Yapeng Tian‡, Yulun Zhang, Yun Fu, Jan Allebach, and Chenliang Xu
CVPR'20: IEEE/CVF Conference on Computer Vision and Pattern Recognition.
TDAN: Temporally Deformable Alignment Network for Video Super-Resolution
Yapeng Tian, Yulun Zhang, Yun Fu, and Chenliang Xu
CVPR'20: IEEE/CVF Conference on Computer Vision and Pattern Recognition.
This is the first work that uses deformable alignment to address video restoration.
ZFusion: Efficient Deep Compositional Zero-shot Learning for Blind Image Super-Resolution with Generative Diffusion Prior
Alireza Esmaeilzehi, Hossein Zaredar, Yapeng Tian, Laleh Seyyed-Kalantari
ICCV'25: IEEE/CVF International Conference on Computer Vision.
DiffIR: Efficient Diffusion Model for Image Restoration
Bin Xia, Yulun Zhang, Shiyin Wang, Yitong Wang, Xinglong Wu, Yapeng Tian, Wenming Yang, Radu Timotfe, Luc Van Gool
TPAMI'25: IEEE Transactions on Pattern Analysis and Machine Intelligence.
DiffIR: Efficient Diffusion Model for Image Restoration
Bin Xia, Yulun Zhang, Shiyin Wang, Yitong Wang, Xinglong Wu, Yapeng Tian, Wenming Yang, Luc Van Gool
ICCV'23: IEEE/CVF International Conference on Computer Vision.
Dual Arbitrary Scale Super-Resolution for Multi-Contrast MRI
Jiamiao Zhang, Yichen Chi, Jun Lyu, Wenming Yang, Yapeng Tian
MICCAI'23: Medical Image Computing and Computer-Assisted Intervention.
Meta-Learning based Degradation Representation for Blind Super-Resolution
Bin Xia, Yapeng Tian, Yulun Zhang, Yucheng Hang, Wenming Yang, Qingmin Liao
TIP'23: IEEE Transactions on Image Processing.
Knowledge Distillation based Degradation Estimation for Blind Super-Resolution
Bin Xia, Yulun Zhang, Yitong Wang, Yapeng Tian, Wenming Yang, Radu Timofte, Luc Van Gool
ICLR'23: International Conference on Learning Representations.
Basic Binary Convolution Unit for Binarized Image Restoration Network
Bin Xia, Yulun Zhang, Yitong Wang, Yapeng Tian, Wenming Yang, Radu Timofte, Luc Van Gool
ICLR'23: International Conference on Learning Representations.
GDSSR: Toward Real-World Ultra-High-Resolution Image Super-Resolution
Yichen Chi, Wenming Yang, Yapeng Tian
SPL'23: IEEE Signal Processing Letters.
DuDoCAF: Dual-Domain Cross-Attention Fusion with Recurrent Transformer for Fast Multi-contrast MR Imaging
Jun Lyu, Bin Sui, Chengyan Wang, Yapeng Tian, Qi Dou, and Jing Qin
MICCAI'22: Medical Image Computing and Computer Assisted Intervention.
Transformer-empowered Multi-contrast MRI Super-Resolution
Guangyuan Li, Jun Lv, Yapeng Tian, Qi Dou, Chengyan Wang, Chenliang Xu, Jing Qin
CVPR'22: IEEE/CVF Conference on Computer Vision and Pattern Recognition.
Coarse-to-Fine Embedded PatchMatch and Multi-Scale Dynamic Aggregation for Reference-based Super-Resolution
Bin Xia, Yapeng Tian, Yucheng Hang, Wenming Yang, Qingmin Liao, Jie Zhou
AAAI'22: The AAAI Conference on Artificial Intelligence.
Efficient Non-Local Contrastive Attention for Image Super-Resolution
Bin Xia‡, Yucheng Hang‡, Yapeng Tian, Wenming Yang, Qingmin Liao, Jie Zhou
AAAI'22: The AAAI Conference on Artificial Intelligence.
Residual Dense Network for Image Super-Resolution
Yulun Zhang, Yapeng Tian, Yu Kong , Bineng Zhong, Yun Fu
TPAMI'20: IEEE Transactions on Pattern Analysis and Machine Intelligence.
CFSNet: Toward a Controllable Feature Space for Image Restoration
Wei Wang‡, Ruiming Guo‡, Yapeng Tian, and Wenming Yang
ICCV'19: IEEE/CVF International Conference on Computer Vision.
LCSCNet: Linear Compressing Based Skip-Connecting Network for ISR
Wenming Yang, Xuechen Zhang, Yapeng Tian, Wei Wang, Jing-Hao Xue, Qingmin Liao
TIP'19: IEEE Trans. Image Processing.
Deep Learning for Single Image Super-Resolution: A Brief Review
Wenming Yang, Xuechen Zhang, Yapeng Tian, Wei Wang, JingHao Xue, Qingmin Liao
TMM'19: IEEE Trans. Multimedia.
Residual Dense Network for Image Super-Resolution
Yulun Zhang, Yapeng Tian, Yu Kong , Bineng Zhong, Yun Fu
CVPR'18 Spotlight: IEEE/CVF Conf. on Computer Vision and Pattern Recognition.
NTIRE 2017 Challenge on Single Image Super-Resolution: Methods and Results
Timofte et al.
CVPRW'17: CVPR Workshops.
Consistent Coding Scheme for Single-Image Super-Resolution
Wenming Yang, Yapeng Tian, Fei Zhou, Qingmin Liao, Hai Chen, Chenglin Zheng
TMM'16: EEE Trans. Multimedia. (First student author)
Anchored Neighborhood Regression based SISR from Self-examples
Yapeng Tian, Fei Zhou, Wenming Yang, Xuesen Shang, Qingmin Liao
ICIP'16: IEEE International Conference on Image Processing.
SISR Using Clustering-Based Global Regression and Propagation Filtering
Wenming Yang, Yapeng Tian, Fei Zhou, ..., Qingmin Liao
ACPR'15 Oral: Asian Conference on Pattern Recognition. (First student author)
Teaching
- Spring 2026 - CS 6384: Computer Vision
- Fall 2025 - CS 4391: Introduction to Computer Vision
- Spring 2025 - CS 6384: Computer Vision
- Fall 2024 - CS 4391: Introduction to Computer Vision
- Spring 2024 - CS 6384: Computer Vision
- Fall 2023 - CS 4391: Introduction to Computer Vision
- Spring 2023 - CS 6384: Computer Vision
- Fall 2022 - CS 6334: Virtual Reality
Service
Organizer:
- CV4A11y: Workshop on Vision Foundation Models and Generative AI for Accessibility, ICCV 2025
- KnowledgeMR: Workshop on Knowledge-Intensive Multimodal Reasoning, ICCV 2025
- MCL: Workshop on Multimodal Continual Learning, ICCV 2025
- Audio Imagination: AI-Driven Speech, Music, and Sound Generation Workshop, NeurIPS 2024
- ELVM: Efficient Large Vision Models Workshop, CVPR 2024
- Cardiac MRI Reconstruction Challenge, MICCAI 2023
- Tutorial on Audio-Visual Scene Understanding, CVPR 2021
- Tutorial on Audio-Visual Scene Understanding, WACV 2021
Area Chair or Senior Program Committee:
- CVPR: IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025, 2026
- ECCV: European Conference on Computer Vision, 2026
- NeurIPS: Conference on Neural Information Processing Systems, 2025, 2026
- ICLR: International Conference on Learning Representations, 2025, 2026
- AAAI: AAAI Conference on Artificial Intelligence, 2023, 2024, 2025, 2026
- ACL ARR: ACL Rolling Review, 2025,2026
Session Chair:
- AAAI 2023 (Multimodal Learning, Low-Level & Physics-based Vision)
Conference Program Committee/Reviewer:
- CVPR: IEEE/CVF Conference on Computer Vision and Pattern Recognition
- ICCV: IEEE/CVF International Conference on Computer Vision
- ECCV: European Conference on Computer Vision
- NeurIPS: Conference on Neural Information Processing Systems
- ICLR: International Conference on Learning Representations
- AAAI: AAAI Conference on Artificial Intelligence
- ICML: International Conference on Machine Learning
- WACV: Winter Conference on Applications of Computer Vision
- ACCV: Asian Conference on Computer Vision
- MICCAI: International Conference On Medical Image Computing & Computer Assisted Intervention
- SIGGRAPH Asia
- Eurographics
- ISMAR: IEEE International Symposium on Mixed and Augmented Reality
Journal Reviewer:
- TPAMI: IEEE Transactions on Pattern Analysis and Machine Intelligence
- IJCV: International Journal of Computer Vision
- TMLR: The Transactions on Machine Learning Research
- TIP: IEEE Transactions on Image Processing
- TNNLS: IEEE Transactions on Neural Networks and Learning Systems
- TMM: IEEE Transactions on Multimedia
- TCSVT: IEEE Transcations on Circuits and Systems for Video Technology
- TASLP: IEEE/ACM Transactions on Audio, Speech and Language Processing
- Scientific Reports–Nature
- CGF: Computer Graphics Forum
- CVIU: Computer Vision and Image Understanding
- SPIC: Signal Processing: Image Communication
- IEEE Access
Talks and Seminars:
- Bridging Vision and Sound: Audio-visual Scene Perception and Generation
CSE Seminar at the University of Notre Dame, April 2026 - Audio-visual Scene Perception and Generation
Guest lecture@ Texas A&M, April 2025 - Audio-visual Scene Perception and Generation
AIM Seminar @ UNT AI Seminar, Jan. 2025 - Enhancing Image Quality with Deep Learning-Based Super-Resolution: From Natural Scenes to Medical Imaging
AIM Seminar @ UTSW, Oct. 2024 - Learning Semantic-aware Grouping for Weakly-Supervised Audio-Visual Scene Understanding
Sight and Sound Workshop @ CVPR, June 2023 - Human-Multisensory AI Collaboration: Opportunities and Challenges
AV4D Workshop @ ECCV, Oct. 2022 - UTD CS Mixer, Oct. 2022
- Audio-Visual Scene Understanding Towards Unified, Explainable, and Robust Multisensory Perception
KTH Dive-Deep Seminar, Dec. 2021
RIT PhD Colloquium Series, Oct. 2021 - Audio-Visual Video Understanding, IIAI Seminar, Sep. 2021
- The Future of Audio-Visual Research Panel Discussion, VALSE Webinar, Nov. 2021
Awards
CVPR GAZE workshop Best Paper Award, 2026
UTD ECS Faculty Teaching Award, 2026
Research and STEM Spirit Award in Computer Science, UTD, 2025
ACCV Best Paper Honorable Mention Award, 2024
IEEE ISMAR IDEATExR workshop Best Paper Award, 2024
UIST Belonging & Inclusion Best Paper Award, 2024
Amazon Research Award, 2024
Undergraduate Research Apprenticeship Program (URAP) award, 2023, 2024, 2025, 2026
Cisco Faculty Research Award, 2023
AAAI New Faculty Highlights, 2023
CVPR Doctoral Consortium, 2022
Top 10% of High-Scoring Reviewers for NeurIPS, 2020
Outstanding Graduate of Tsinghua University, 2017
Outstanding Master Thesis Award, Tsinghua University, 2017
National Scholarship, Tsinghua University, 2016
Vitæ
Full CV in PDF.
-
University of Texas at Dallas 2022 - nowAssistant Professor
Department of Computer Science -
University of Rochester 2017 - 2022Ph.D. Student
Department of Computer Science -
Meta Sep. 2021 - Jan. 2022Research Intern
Reality Labs -
Adobe Summer 2021Research Intern
Creative Intelligence Lab -
Adobe Summer 2019Research Intern
Creative Intelligence Lab -
Tsinghua University 2014-2017M.E. Student
Department of Electronic Engineering -
Chinese Academy of Sciences Nov. 2016- May 2017Visiting Student
Shenzhen Institutes of Advanced Technology -
Xidian University 2009 - 2013B.E. Student
School of Electronic Engineering
This website was built with jekyll based on a template from Martin Saveski.